 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeMS: Deep Spiking Neural Network for Motion Segmentation
May 13, 2021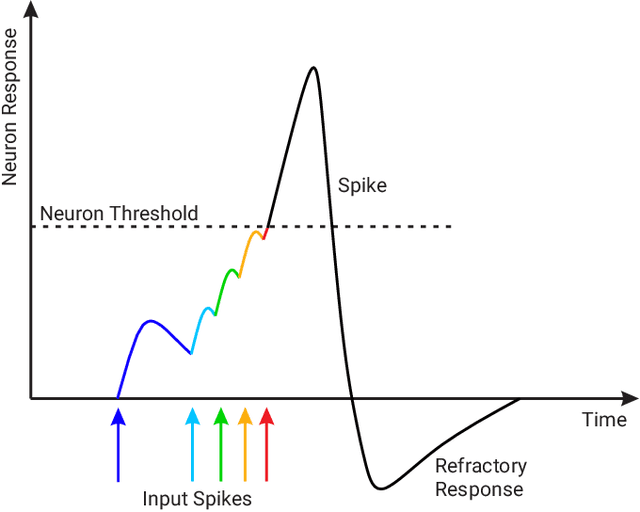
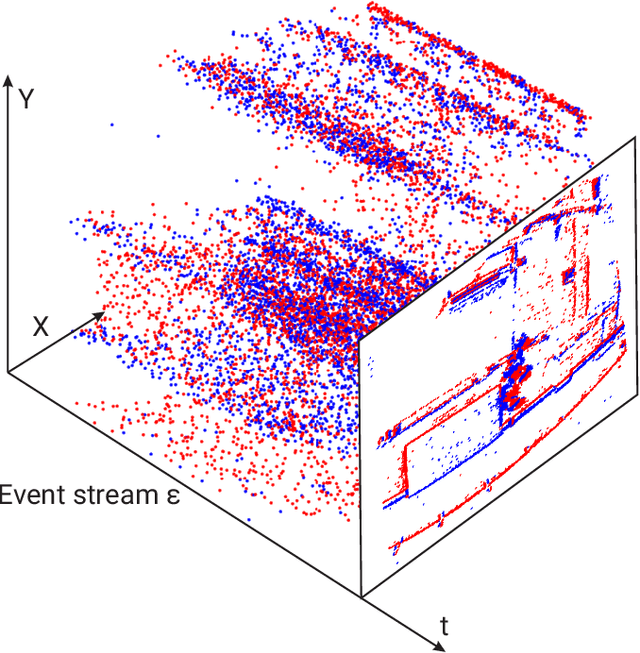
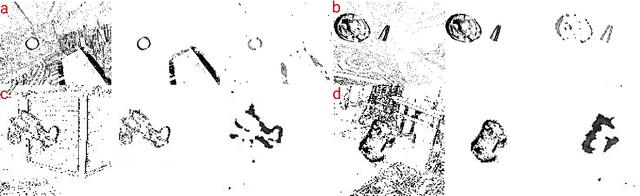
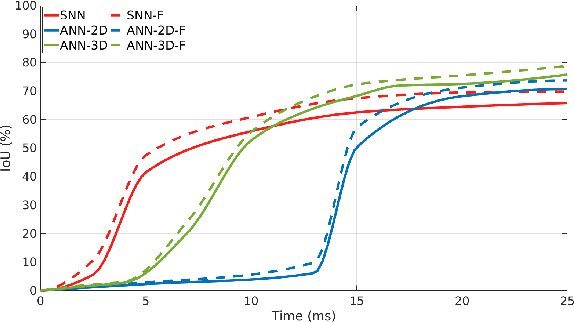
Spiking Neural Networks (SNN) are the so-called third generation of neural networks which attempt to more closely match the functioning of the biological brain. They inherently encode temporal data, allowing for training with less energy usage and can be extremely energy efficient when coded on neuromorphic hardware. In addition, they are well suited for tasks involving event-based sensors, which match the event-based nature of the SNN. However, SNNs have not been as effectively applied to real-world, large-scale tasks as standard Artificial Neural Networks (ANNs) due to the algorithmic and training complexity. To exacerbate the situation further, the input representation is unconventional and requires careful analysis and deep understanding. In this paper, we propose \textit{SpikeMS}, the first deep encoder-decoder SNN architecture for the real-world large-scale problem of motion segmentation using the event-based DVS camera as input. To accomplish this, we introduce a novel spatio-temporal loss formulation that includes both spike counts and classification labels in conjunction with the use of new techniques for SNN backpropagation. In addition, we show that \textit{SpikeMS} is capable of \textit{incremental predictions}, or predictions from smaller amounts of test data than it is trained on. This is invaluable for providing outputs even with partial input data for low-latency applications and those requiring fast predictions. We evaluated \textit{SpikeMS} on challenging synthetic and real-world sequences from EV-IMO, EED and MOD datasets and achieving results on a par with a comparable ANN method, but using potentially 50 times less power.