 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomizing Large Language Model Generation Style using Parameter-Efficient Finetuning
Paper and Code

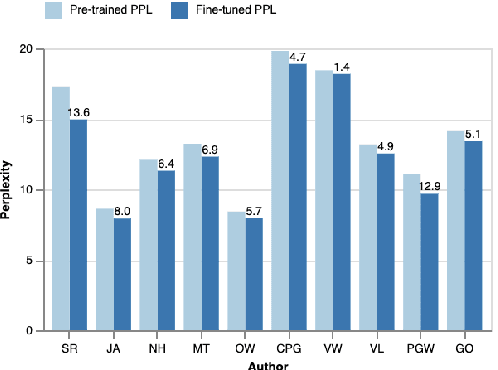
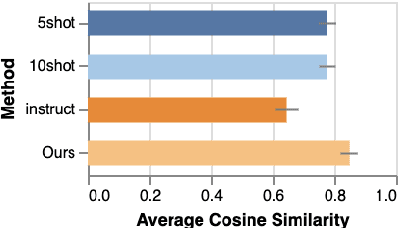
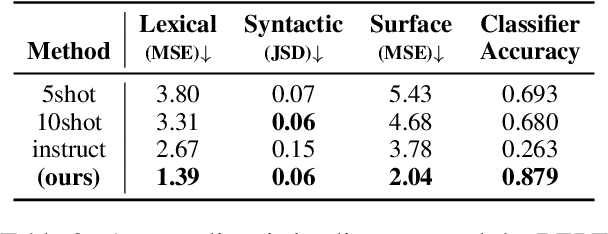
One-size-fits-all large language models (LLMs) are increasingly being used to help people with their writing. However, the style these models are trained to write in may not suit all users or use cases. LLMs would be more useful as writing assistants if their idiolect could be customized to match each user. In this paper, we explore whether parameter-efficient finetuning (PEFT) with Low-Rank Adaptation can effectively guide the style of LLM generations. We use this method to customize LLaMA-2 to ten different authors and show that the generated text has lexical, syntactic, and surface alignment with the target author but struggles with content memorization. Our findings highlight the potential of PEFT to support efficient, user-level customization of LLMs.