 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperShaper: Task-Agnostic Super Pre-training of BERT Models with Variable Hidden Dimensions
Oct 10, 2021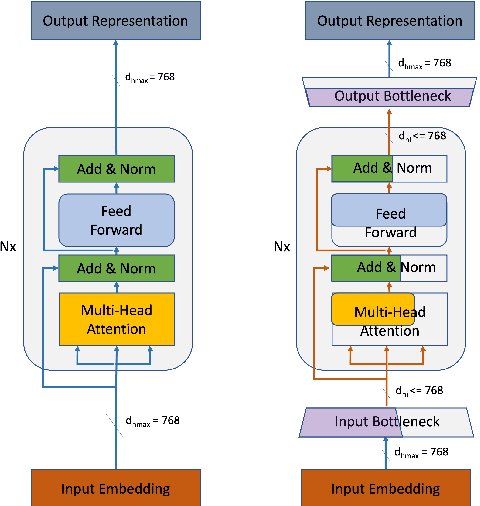
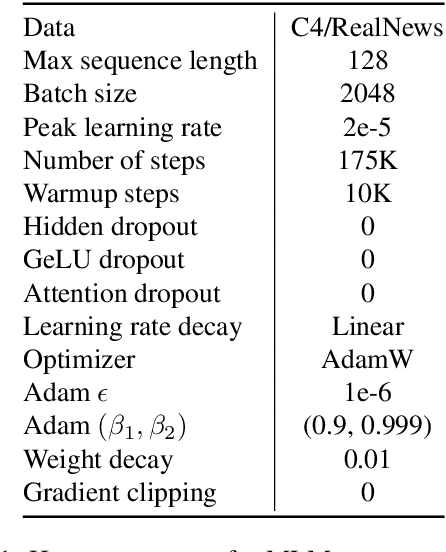
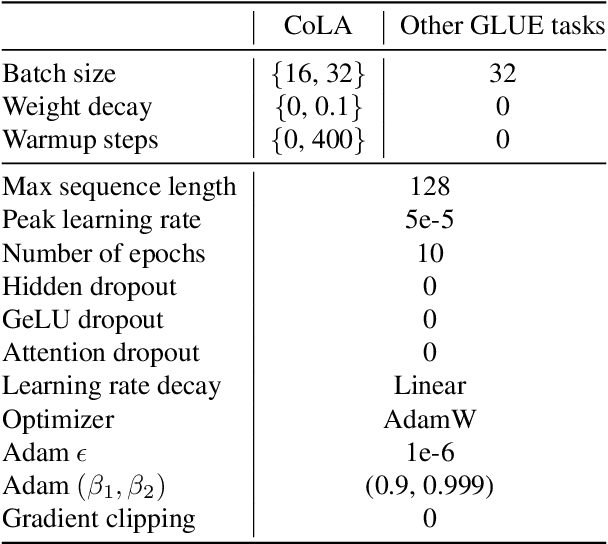
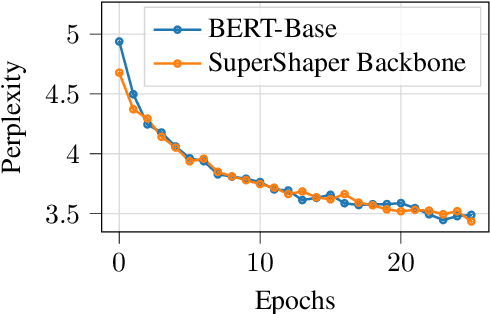
Task-agnostic pre-training followed by task-specific fine-tuning is a default approach to train NLU models. Such models need to be deployed on devices across the cloud and the edge with varying resource and accuracy constraints. For a given task, repeating pre-training and fine-tuning across tens of devices is prohibitively expensive. We propose SuperShaper, a task agnostic pre-training approach which simultaneously pre-trains a large number of Transformer models by varying shapes, i.e., by varying the hidden dimensions across layers. This is enabled by a backbone network with linear bottleneck matrices around each Transformer layer which are sliced to generate differently shaped sub-networks. In spite of its simple design space and efficient implementation, SuperShaper discovers networks that effectively trade-off accuracy and model size: Discovered networks are more accurate than a range of hand-crafted and automatically searched networks on GLUE benchmarks. Further, we find two critical advantages of shape as a design variable for Neural Architecture Search (NAS): (a) heuristics of good shapes can be derived and networks found with these heuristics match and even improve on carefully searched networks across a range of parameter counts, and (b) the latency of networks across multiple CPUs and GPUs are insensitive to the shape and thus enable device-agnostic search. In summary, SuperShaper radically simplifies NAS for language models and discovers networks that generalize across tasks, parameter constraints, and devices.
Design and Scaffolded Training of an Efficient DNN Operator for Computer Vision on the Edge
Aug 25, 2021



Massively parallel systolic arrays and resource-efficient depthwise separable convolutions are two promising techniques to accelerate DNN inference on the edge. Interestingly, their combination is inefficient: Computational patterns of depthwise separable convolutions do not exhibit a rhythmic systolic flow and lack sufficient data reuse to saturate systolic arrays. We formally analyse this inefficiency and propose an efficient operator, an optimal hardware dataflow, and a superior training methodology towards alleviating this. The efficient operator, called FuSeConv, is a drop-in replacement for depthwise separable convolutions. FuSeConv factorizes convolution fully along their spatial and depth dimensions. The resultant computation efficiently maps to systolic arrays. The optimal dataflow, called Spatial-Tiled Output Stationary (ST-OS), maximizes the efficiency of FuSeConv on systolic arrays. It maps independent convolutions to rows of the array to maximize resource utilization with negligible VLSI overheads. Neural Operator Scaffolding (NOS) scaffolds the training of FuSeConv by distilling knowledge from the expensive depthwise separable convolutions. This bridges the accuracy gap between FuSeConv networks and baselines. Additionally, NOS can be combined with Neural Architecture Search (NAS) to trade-off latency and accuracy. The HW/SW co-design of FuSeConv with ST-OS achieves a significant speedup of 4.1-9.25X with state-of-the-art efficient networks for ImageNet. The parameter efficiency of FuSeConv and its significant out-performance over depthwise separable convolutions on systolic arrays illustrates their promise as a strong solution on the edge. Training FuSeConv networks with NOS achieves accuracy comparable to the baselines. Further, by combining NOS with NAS, we design networks that define state-of-the-art models improving on both accuracy and latency on systolic arrays.
FuSeConv: Fully Separable Convolutions for Fast Inference on Systolic Arrays
May 27, 2021Both efficient neural networks and hardware accelerators are being explored to speed up DNN inference on edge devices. For example, MobileNet uses depthwise separable convolution to achieve much lower latency, while systolic arrays provide much higher performance per watt. Interestingly however, the combination of these two ideas is inefficient: The computational patterns of depth-wise separable convolution are not systolic and lack data reuse to saturate the systolic array's constrained dataflow. In this paper, we propose FuSeConv (Fully-Separable Convolution) as a drop-in replacement for depth-wise separable convolution. FuSeConv generalizes the decomposition of convolutions fully to separable 1D convolutions along spatial and depth dimensions. The resultant computation is systolic and efficiently utilizes the systolic array with a slightly modified dataflow. With FuSeConv, we achieve a significant speed-up of 3x-7x with the MobileNet family of networks on a systolic array of size 64x64, with comparable accuracy on the ImageNet dataset. The high speed-up motivates exploration of hardware-aware Neural Operator Search (NOS) in complement to ongoing efforts on Neural Architecture Search (NAS).