 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperShaper: Task-Agnostic Super Pre-training of BERT Models with Variable Hidden Dimensions
Paper and Code
Oct 10, 2021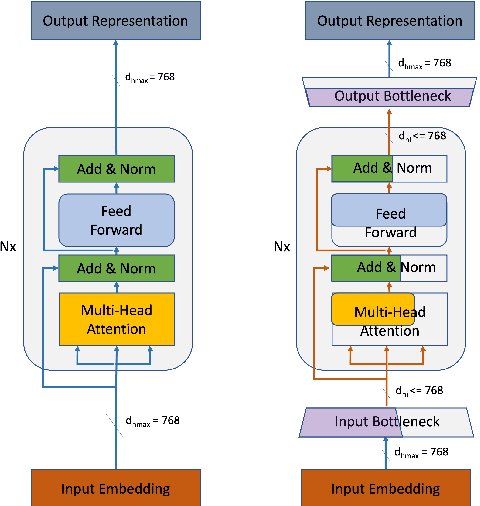
Task-agnostic pre-training followed by task-specific fine-tuning is a default approach to train NLU models. Such models need to be deployed on devices across the cloud and the edge with varying resource and accuracy constraints. For a given task, repeating pre-training and fine-tuning across tens of devices is prohibitively expensive. We propose SuperShaper, a task agnostic pre-training approach which simultaneously pre-trains a large number of Transformer models by varying shapes, i.e., by varying the hidden dimensions across layers. This is enabled by a backbone network with linear bottleneck matrices around each Transformer layer which are sliced to generate differently shaped sub-networks. In spite of its simple design space and efficient implementation, SuperShaper discovers networks that effectively trade-off accuracy and model size: Discovered networks are more accurate than a range of hand-crafted and automatically searched networks on GLUE benchmarks. Further, we find two critical advantages of shape as a design variable for Neural Architecture Search (NAS): (a) heuristics of good shapes can be derived and networks found with these heuristics match and even improve on carefully searched networks across a range of parameter counts, and (b) the latency of networks across multiple CPUs and GPUs are insensitive to the shape and thus enable device-agnostic search. In summary, SuperShaper radically simplifies NAS for language models and discovers networks that generalize across tasks, parameter constraints, and devices.