 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cost of Compression: Investigating the Impact of Compression on Parametric Knowledge in Language Models
Dec 01, 2023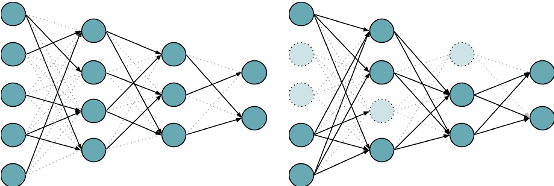


Compressing large language models (LLMs), often consisting of billions of parameters, provides faster inference, smaller memory footprints, and enables local deployment. Two standard compression techniques are pruning and quantization, with the former eliminating redundant connections in model layers and the latter representing model parameters with fewer bits. The key tradeoff is between the degree of compression and the impact on the quality of the compressed model. Existing research on LLM compression primarily focuses on performance in terms of general metrics like perplexity or downstream task accuracy. More fine-grained metrics, such as those measuring parametric knowledge, remain significantly underexplored. To help bridge this gap, we present a comprehensive analysis across multiple model families (ENCODER, ENCODER-DECODER, and DECODER) using the LAMA and LM-HARNESS benchmarks in order to systematically quantify the effect of commonly employed compression techniques on model performance. A particular focus is on tradeoffs involving parametric knowledge, with the goal of providing practitioners with practical insights to help make informed decisions on compression. We release our codebase1 to enable further research.
NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails
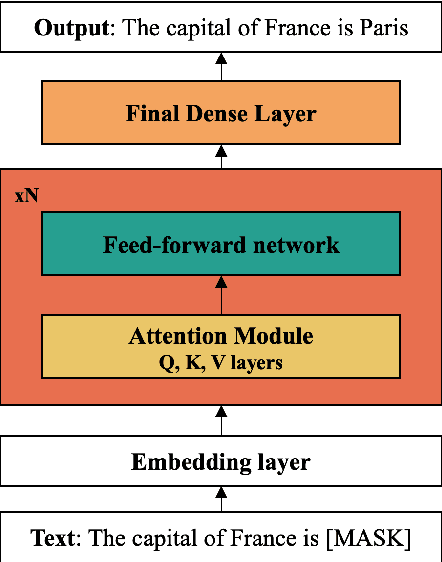
Oct 16, 2023NeMo Guardrails is an open-source toolkit for easily adding programmable guardrails to LLM-based conversational systems. Guardrails (or rails for short) are a specific way of controlling the output of an LLM, such as not talking about topics considered harmful, following a predefined dialogue path, using a particular language style, and more. There are several mechanisms that allow LLM providers and developers to add guardrails that are embedded into a specific model at training, e.g. using model alignment. Differently, using a runtime inspired from dialogue management, NeMo Guardrails allows developers to add programmable rails to LLM applications - these are user-defined, independent of the underlying LLM, and interpretable. Our initial results show that the proposed approach can be used with several LLM providers to develop controllable and safe LLM applications using programmable rails.
Single Sequence Prediction over Reasoning Graphs for Multi-hop QA
Jul 01, 2023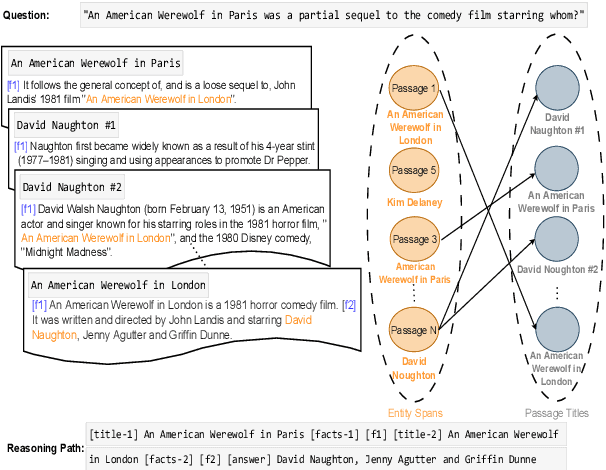
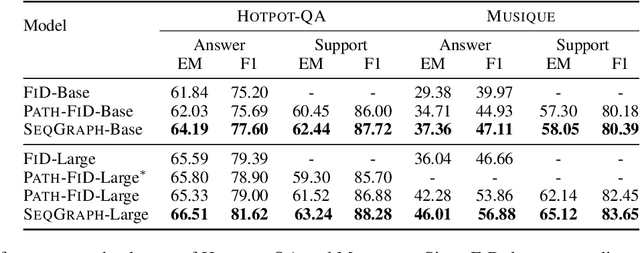
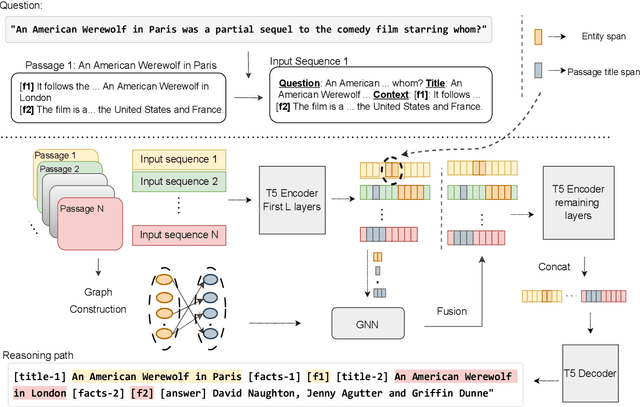
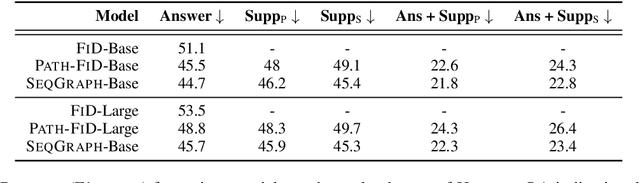
Recent generative approaches for multi-hop question answering (QA) utilize the fusion-in-decoder method~\cite{izacard-grave-2021-leveraging} to generate a single sequence output which includes both a final answer and a reasoning path taken to arrive at that answer, such as passage titles and key facts from those passages. While such models can lead to better interpretability and high quantitative scores, they often have difficulty accurately identifying the passages corresponding to key entities in the context, resulting in incorrect passage hops and a lack of faithfulness in the reasoning path. To address this, we propose a single-sequence prediction method over a local reasoning graph (\model)\footnote{Code/Models will be released at \url{https://github.com/gowtham1997/SeqGraph}} that integrates a graph structure connecting key entities in each context passage to relevant subsequent passages for each question. We use a graph neural network to encode this graph structure and fuse the resulting representations into the entity representations of the model. Our experiments show significant improvements in answer exact-match/F1 scores and faithfulness of grounding in the reasoning path on the HotpotQA dataset and achieve state-of-the-art numbers on the Musique dataset with only up to a 4\% increase in model parameters.