 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartOracle - An Agentic Approach to Mitigate Noise in Differential Oracles
Jan 21, 2026Differential fuzzers detect bugs by executing identical inputs across distinct implementations of the same specification, such as JavaScript interpreters. Validating the outputs requires an oracle and for differential testing of JavaScript, these are constructed manually, making them expensive, time-consuming, and prone to false positives. Worse, when the specification evolves, this manual effort must be repeated. Inspired by the success of agentic systems in other SE domains, this paper introduces SmartOracle. SmartOracle decomposes the manual triage workflow into specialized Large Language Model (LLM) sub-agents. These agents synthesize independently gathered evidence from terminal runs and targeted specification queries to reach a final verdict. For historical benchmarks, SmartOracle achieves 0.84 recall with an 18% false positive rate. Compared to a sequential Gemini 2.5 Pro baseline, it improves triage accuracy while reducing analysis time by 4$\times$ and API costs by 10$\times$. In active fuzzing campaigns, SmartOracle successfully identified and reported previously unknown specification-level issues across major engines, including bugs in V8, JavaScriptCore, and GraalJS. The success of SmartOracle's agentic architecture on Javascript suggests it might be useful other software systems- a research direction we will explore in future work.
Extracting Usable Predictions from Quantized Networks through Uncertainty Quantification for OOD Detection
Mar 02, 2024OOD detection has become more pertinent with advances in network design and increased task complexity. Identifying which parts of the data a given network is misclassifying has become as valuable as the network's overall performance. We can compress the model with quantization, but it suffers minor performance loss. The loss of performance further necessitates the need to derive the confidence estimate of the network's predictions. In line with this thinking, we introduce an Uncertainty Quantification(UQ) technique to quantify the uncertainty in the predictions from a pre-trained vision model. We subsequently leverage this information to extract valuable predictions while ignoring the non-confident predictions. We observe that our technique saves up to 80% of ignored samples from being misclassified. The code for the same is available here.
The Cost of Compression: Investigating the Impact of Compression on Parametric Knowledge in Language Models
Dec 01, 2023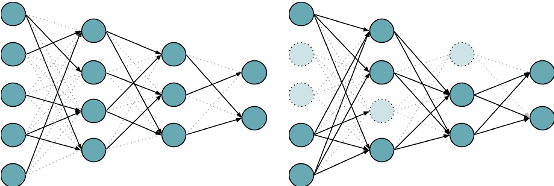


Compressing large language models (LLMs), often consisting of billions of parameters, provides faster inference, smaller memory footprints, and enables local deployment. Two standard compression techniques are pruning and quantization, with the former eliminating redundant connections in model layers and the latter representing model parameters with fewer bits. The key tradeoff is between the degree of compression and the impact on the quality of the compressed model. Existing research on LLM compression primarily focuses on performance in terms of general metrics like perplexity or downstream task accuracy. More fine-grained metrics, such as those measuring parametric knowledge, remain significantly underexplored. To help bridge this gap, we present a comprehensive analysis across multiple model families (ENCODER, ENCODER-DECODER, and DECODER) using the LAMA and LM-HARNESS benchmarks in order to systematically quantify the effect of commonly employed compression techniques on model performance. A particular focus is on tradeoffs involving parametric knowledge, with the goal of providing practitioners with practical insights to help make informed decisions on compression. We release our codebase1 to enable further research.