 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeaning Representation of Numeric Fused-Heads in UCCA
Paper and Code
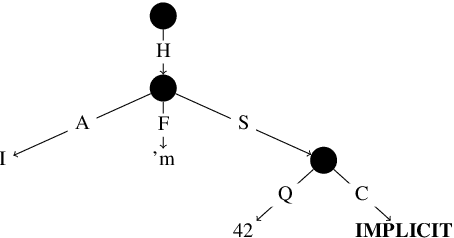

We exhibit that the implicit UCCA parser does not address numeric fused-heads (NFHs) consistently, which could result either from inconsistent annotation, insufficient training data or a modelling limitation. and show which factors are involved. We consider this phenomenon important, as it is pervasive in text and critical for correct inference. Careful design and fine-grained annotation of NFHs in meaning representation frameworks would benefit downstream tasks such as machine translation, natural language inference and question answering, particularly when they require numeric reasoning, as recovering and categorizing them. We are investigating the treatment of this phenomenon by other meaning representations, such as AMR. We encourage researchers in meaning representations, and computational linguistics in general, to address this phenomenon in future research.