 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Self Consistency in LLMs through Probabilistic Tokenization
Paper and Code

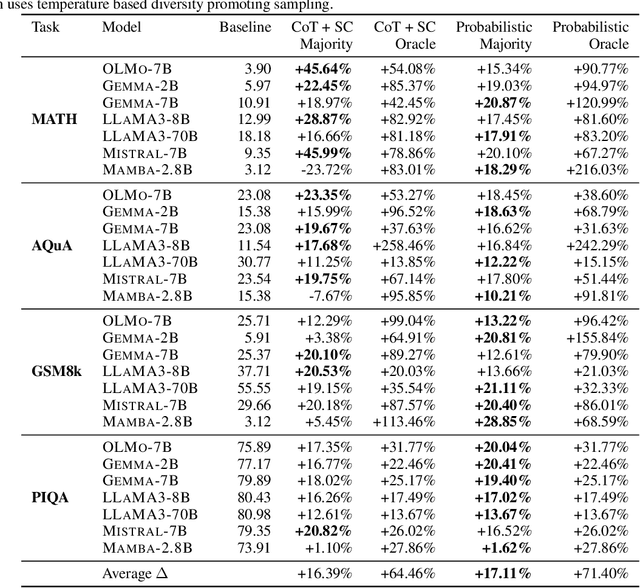

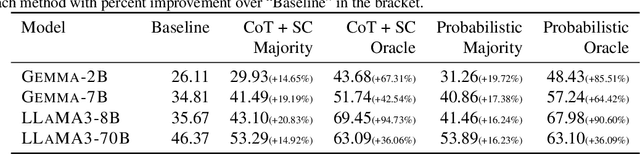
Prior research has demonstrated noticeable performance gains through the use of probabilistic tokenizations, an approach that involves employing multiple tokenizations of the same input string during the training phase of a language model. Despite these promising findings, modern large language models (LLMs) have yet to be trained using probabilistic tokenizations. Interestingly, while the tokenizers of these contemporary LLMs have the capability to generate multiple tokenizations, this property remains underutilized. In this work, we propose a novel method to leverage the multiple tokenization capabilities of modern LLM tokenizers, aiming to enhance the self-consistency of LLMs in reasoning tasks. Our experiments indicate that when utilizing probabilistic tokenizations, LLMs generate logically diverse reasoning paths, moving beyond mere surface-level linguistic diversity.We carefully study probabilistic tokenization and offer insights to explain the self consistency improvements it brings through extensive experimentation on 5 LLM families and 4 reasoning benchmarks.