 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Spurious Features can Hurt Accuracy and Affect Groups Disproportionately
Paper and Code
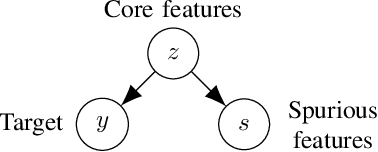


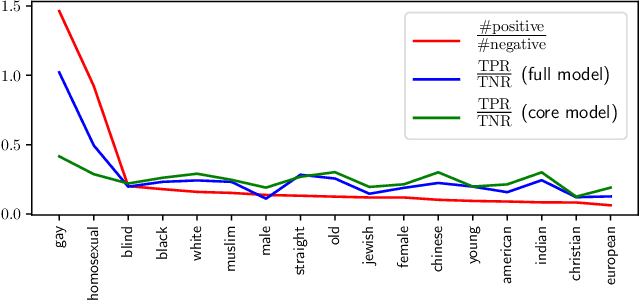
The presence of spurious features interferes with the goal of obtaining robust models that perform well across many groups within the population. A natural remedy is to remove spurious features from the model. However, in this work we show that removal of spurious features can decrease accuracy due to the inductive biases of overparameterized models. We completely characterize how the removal of spurious features affects accuracy across different groups (more generally, test distributions) in noiseless overparameterized linear regression. In addition, we show that removal of spurious feature can decrease the accuracy even in balanced datasets -- each target co-occurs equally with each spurious feature; and it can inadvertently make the model more susceptible to other spurious features. Finally, we show that robust self-training can remove spurious features without affecting the overall accuracy. Experiments on the Toxic-Comment-Detectoin and CelebA datasets show that our results hold in non-linear models.