 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast, Imitate, Adapt: Learning Robotic Skills From Raw Human Videos
Aug 10, 2024Learning robotic skills from raw human videos remains a non-trivial challenge. Previous works tackled this problem by leveraging behavior cloning or learning reward functions from videos. Despite their remarkable performances, they may introduce several issues, such as the necessity for robot actions, requirements for consistent viewpoints and similar layouts between human and robot videos, as well as low sample efficiency. To this end, our key insight is to learn task priors by contrasting videos and to learn action priors through imitating trajectories from videos, and to utilize the task priors to guide trajectories to adapt to novel scenarios. We propose a three-stage skill learning framework denoted as Contrast-Imitate-Adapt (CIA). An interaction-aware alignment transformer is proposed to learn task priors by temporally aligning video pairs. Then a trajectory generation model is used to learn action priors. To adapt to novel scenarios different from human videos, the Inversion-Interaction method is designed to initialize coarse trajectories and refine them by limited interaction. In addition, CIA introduces an optimization method based on semantic directions of trajectories for interaction security and sample efficiency. The alignment distances computed by IAAformer are used as the rewards. We evaluate CIA in six real-world everyday tasks, and empirically demonstrate that CIA significantly outperforms previous state-of-the-art works in terms of task success rate and generalization to diverse novel scenarios layouts and object instances.
Goal-Conditioned Reinforcement Learning with Disentanglement-based Reachability Planning
Jul 20, 2023Goal-Conditioned Reinforcement Learning (GCRL) can enable agents to spontaneously set diverse goals to learn a set of skills. Despite the excellent works proposed in various fields, reaching distant goals in temporally extended tasks remains a challenge for GCRL. Current works tackled this problem by leveraging planning algorithms to plan intermediate subgoals to augment GCRL. Their methods need two crucial requirements: (i) a state representation space to search valid subgoals, and (ii) a distance function to measure the reachability of subgoals. However, they struggle to scale to high-dimensional state space due to their non-compact representations. Moreover, they cannot collect high-quality training data through standard GC policies, which results in an inaccurate distance function. Both affect the efficiency and performance of planning and policy learning. In the paper, we propose a goal-conditioned RL algorithm combined with Disentanglement-based Reachability Planning (REPlan) to solve temporally extended tasks. In REPlan, a Disentangled Representation Module (DRM) is proposed to learn compact representations which disentangle robot poses and object positions from high-dimensional observations in a self-supervised manner. A simple REachability discrimination Module (REM) is also designed to determine the temporal distance of subgoals. Moreover, REM computes intrinsic bonuses to encourage the collection of novel states for training. We evaluate our REPlan in three vision-based simulation tasks and one real-world task. The experiments demonstrate that our REPlan significantly outperforms the prior state-of-the-art methods in solving temporally extended tasks.
Weakly Supervised Disentangled Representation for Goal-conditioned Reinforcement Learning
Feb 28, 2022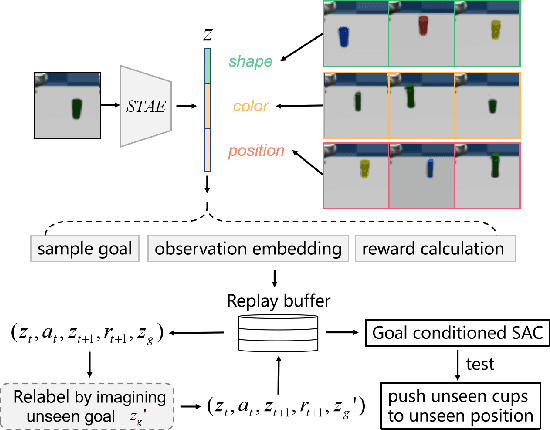


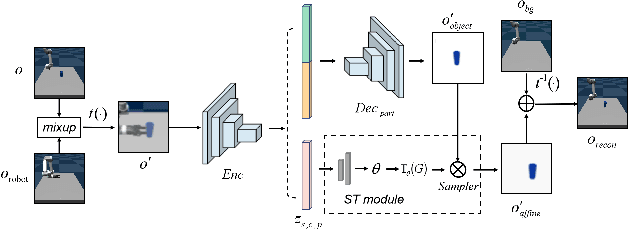
Goal-conditioned reinforcement learning is a crucial yet challenging algorithm which enables agents to achieve multiple user-specified goals when learning a set of skills in a dynamic environment. However, it typically requires millions of the environmental interactions explored by agents, which is sample-inefficient. In the paper, we propose a skill learning framework DR-GRL that aims to improve the sample efficiency and policy generalization by combining the Disentangled Representation learning and Goal-conditioned visual Reinforcement Learning. In a weakly supervised manner, we propose a Spatial Transform AutoEncoder (STAE) to learn an interpretable and controllable representation in which different parts correspond to different object attributes (shape, color, position). Due to the high controllability of the representations, STAE can simply recombine and recode the representations to generate unseen goals for agents to practice themselves. The manifold structure of the learned representation maintains consistency with the physical position, which is beneficial for reward calculation. We empirically demonstrate that DR-GRL significantly outperforms the previous methods in sample efficiency and policy generalization. In addition, DR-GRL is also easy to expand to the real robot.
* 8 pages; Accepted by RAL with ICRA 2022