 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking an Emotional Look at Video Paragraph Captioning
Paper and Code
Mar 12, 2022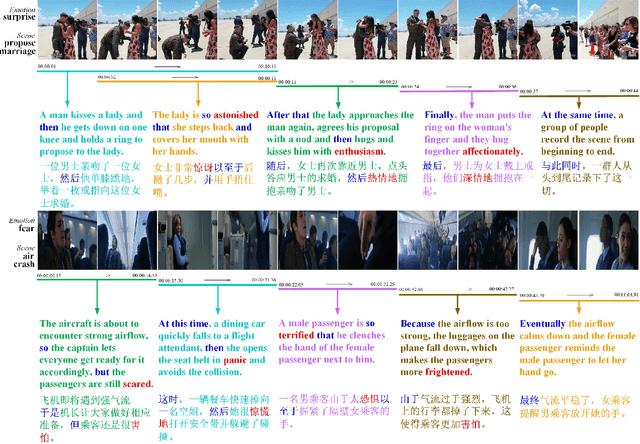
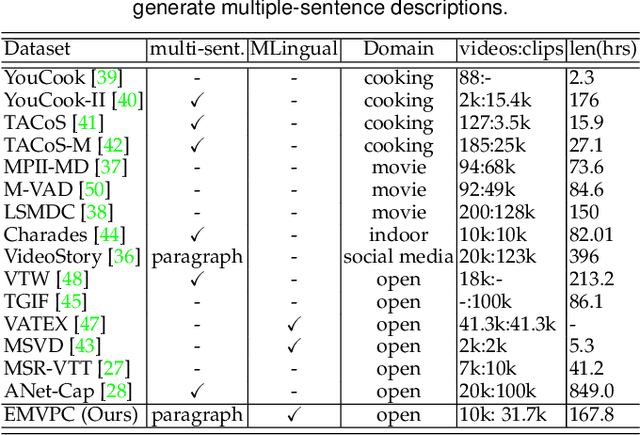
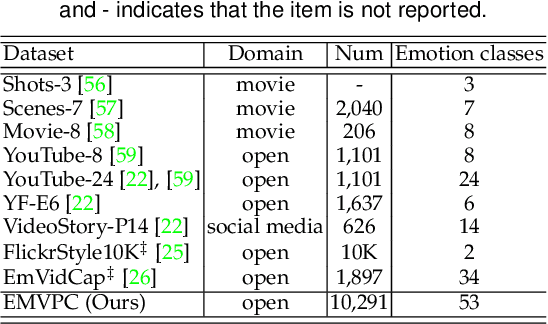
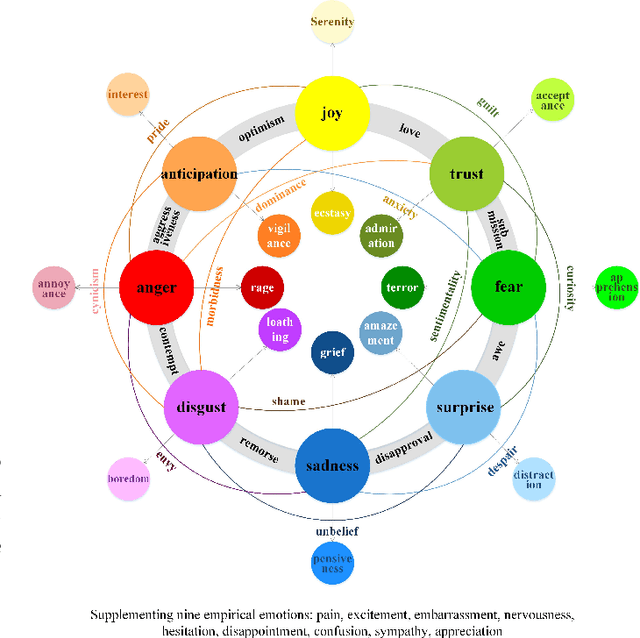
Translating visual data into natural language is essential for machines to understand the world and interact with humans. In this work, a comprehensive study is conducted on video paragraph captioning, with the goal to generate paragraph-level descriptions for a given video. However, current researches mainly focus on detecting objective facts, ignoring the needs to establish the logical associations between sentences and to discover more accurate emotions related to video contents. Such a problem impairs fluent and abundant expressions of predicted captions, which are far below human language tandards. To solve this problem, we propose to construct a large-scale emotion and logic driven multilingual dataset for this task. This dataset is named EMVPC (standing for "Emotional Video Paragraph Captioning") and contains 53 widely-used emotions in daily life, 376 common scenes corresponding to these emotions, 10,291 high-quality videos and 20,582 elaborated paragraph captions with English and Chinese versions. Relevant emotion categories, scene labels, emotion word labels and logic word labels are also provided in this new dataset. The proposed EMVPC dataset intends to provide full-fledged video paragraph captioning in terms of rich emotions, coherent logic and elaborate expressions, which can also benefit other tasks in vision-language fields. Furthermore, a comprehensive study is conducted through experiments on existing benchmark video paragraph captioning datasets and the proposed EMVPC. The stateof-the-art schemes from different visual captioning tasks are compared in terms of 15 popular metrics, and their detailed objective as well as subjective results are summarized. Finally, remaining problems and future directions of video paragraph captioning are also discussed. The unique perspective of this work is expected to boost further development in video paragraph captioning research.