 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-thinking Co-Salient Object Detection
Paper and Code


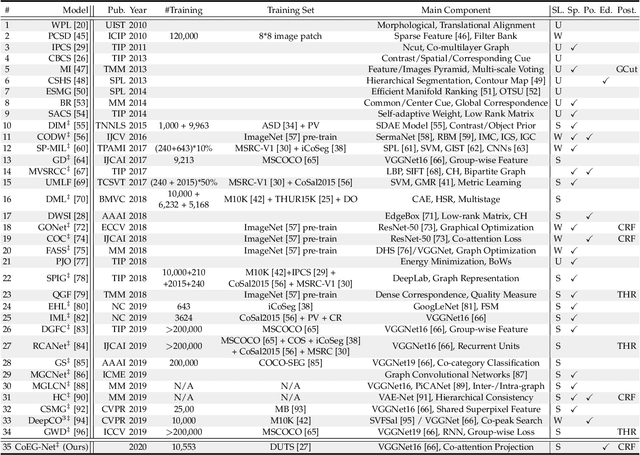

In this paper, we conduct a comprehensive study on the co-salient object detection (CoSOD) problem for images. CoSOD is an emerging and rapidly growing extension of salient object detection (SOD), which aims to detect the co-occurring salient objects in a group of images. However, existing CoSOD datasets often have a serious data bias, assuming that each group of images contains salient objects of similar visual appearances. This bias can lead to the ideal settings and effectiveness of models trained on existing datasets, being impaired in real-life situations, where similarities are usually semantic or conceptual. To tackle this issue, we first introduce a new benchmark, called CoSOD3k in the wild, which requires a large amount of semantic context, making it more challenging than existing CoSOD datasets. Our CoSOD3k consists of 3,316 high-quality, elaborately selected images divided into 160 groups with hierarchical annotations. The images span a wide range of categories, shapes, object sizes, and backgrounds. Second, we integrate the existing SOD techniques to build a unified, trainable CoSOD framework, which is long overdue in this field. Specifically, we propose a novel CoEG-Net that augments our prior model EGNet with a co-attention projection strategy to enable fast common information learning. CoEG-Net fully leverages previous large-scale SOD datasets and significantly improves the model scalability and stability. Third, we comprehensively summarize 34 cutting-edge algorithms, benchmarking 16 of them over three challenging CoSOD datasets (iCoSeg, CoSal2015, and our CoSOD3k), and reporting more detailed (i.e., group-level) performance analysis. Finally, we discuss the challenges and future works of CoSOD. We hope that our study will give a strong boost to growth in the CoSOD community