 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Semantic Weak Generalization Problem in Generative Zero-Shot Learning: Ante-hoc and Post-hoc
Paper and Code

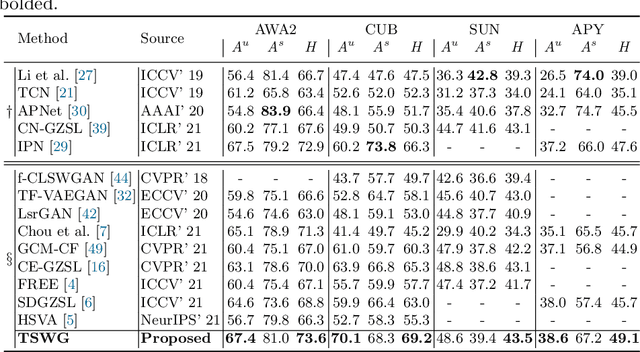
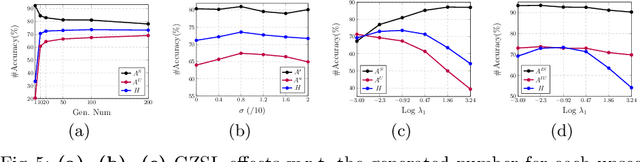
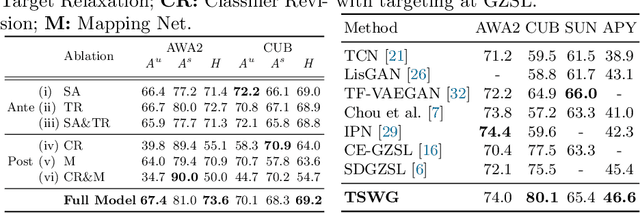
In this paper, we present a simple and effective strategy lowering the previously unexplored factors that limit the performance ceiling of generative Zero-Shot Learning (ZSL). We begin by formally defining semantic generalization, then look into approaches for reducing the semantic weak generalization problem and minimizing its negative influence on classifier training. In the ante-hoc phase, we augment the generator's semantic input, as well as relax the fitting target of the generator. In the post-hoc phase (after generating simulated unseen samples), we derive from the gradient of the loss function to minimize the gradient increment on seen classifier weights carried by biased unseen distribution, which tends to cause misleading on intra-seen class decision boundaries. Without complicated designs, our approach hit the essential problem and significantly outperform the state-of-the-art on four widely used ZSL datasets.