 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-aware Density Map for Crowd Counting and Density Estimation
Paper and Code
Jun 17, 2019
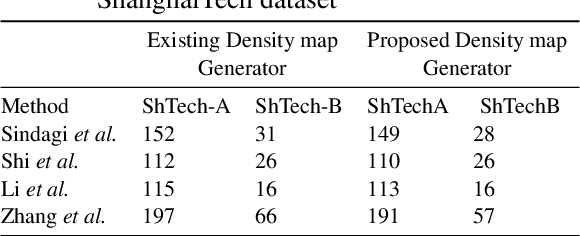
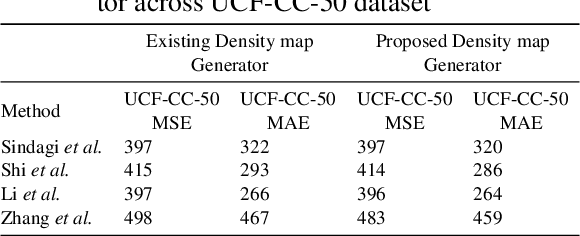

Precise knowledge about the size of a crowd, its density and flow can provide valuable information for safety and security applications, event planning, architectural design and to analyze consumer behavior. Creating a powerful machine learning model, to employ for such applications requires a large and highly accurate and reliable dataset. Unfortunately the existing crowd counting and density estimation benchmark datasets are not only limited in terms of their size, but also lack annotation, in general too time consuming to implement. This paper attempts to address this very issue through a content aware technique, uses combinations of Chan-Vese segmentation algorithm, two-dimensional Gaussian filter and brute-force nearest neighbor search. The results shows that by simply replacing the commonly used density map generators with the proposed method, higher level of accuracy can be achieved using the existing state of the art models.