 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Self-Learning: Semi-Supervised Improvement to Dataset Volumes and Model Accuracy
Jun 06, 2019
A novel semi-supervised learning technique is introduced based on a simple iterative learning cycle together with learned thresholding techniques and an ensemble decision support system. State-of-the-art model performance and increased training data volume are demonstrated, through the use of unlabelled data when training deeply learned classification models. Evaluation of the proposed approach is performed on commonly used datasets when evaluating semi-supervised learning techniques as well as a number of more challenging image classification datasets (CIFAR-100 and a 200 class subset of ImageNet).
A Comparison of Embedded Deep Learning Methods for Person Detection
Jan 08, 2019
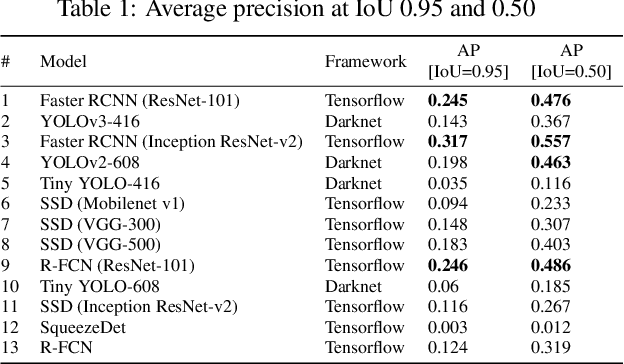


Recent advancements in parallel computing, GPU technology and deep learning provide a new platform for complex image processing tasks such as person detection to flourish. Person detection is fundamental preliminary operation for several high level computer vision tasks. One industry that can significantly benefit from person detection is retail. In recent years, various studies attempt to find an optimal solution for person detection using neural networks and deep learning. This study conducts a comparison among the state of the art deep learning base object detector with the focus on person detection performance in indoor environments. Performance of various implementations of YOLO, SSD, RCNN, R-FCN and SqueezeDet have been assessed using our in-house proprietary dataset which consists of over 10 thousands indoor images captured form shopping malls, retails and stores. Experimental results indicate that, Tiny YOLO-416 and SSD (VGG-300) are the fastest and Faster-RCNN (Inception ResNet-v2) and R-FCN (ResNet-101) are the most accurate detectors investigated in this study. Further analysis shows that YOLO v3-416 delivers relatively accurate result in a reasonable amount of time, which makes it an ideal model for person detection in embedded platforms.
Summarizing Videos with Attention
Dec 05, 2018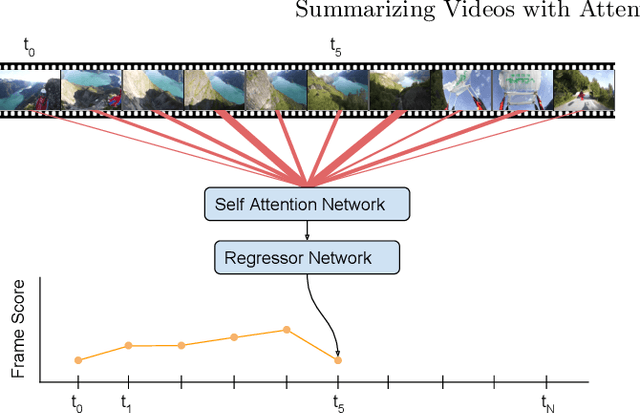

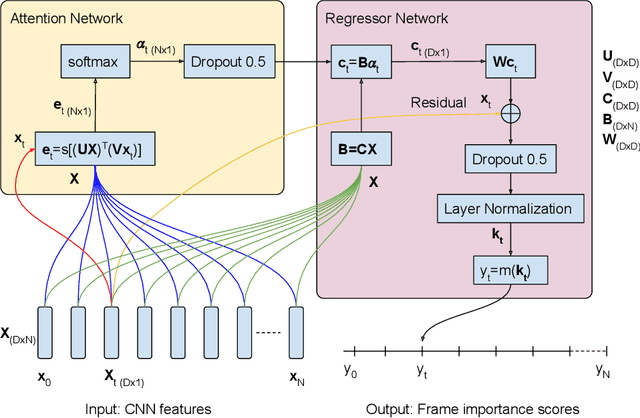
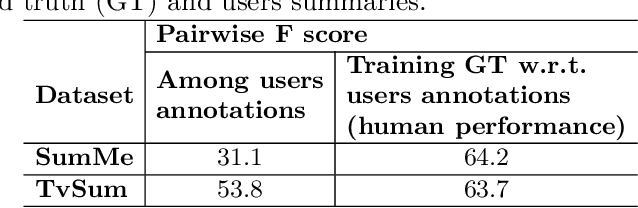
In this work we propose a novel method for supervised, keyshots based video summarization by applying a conceptually simple and computationally efficient soft, self-attention mechanism. Current state of the art methods leverage bi-directional recurrent networks such as BiLSTM combined with attention. These networks are complex to implement and computationally demanding compared to fully connected networks. To that end we propose a simple, self-attention based network for video summarization which performs the entire sequence to sequence transformation in a single feed forward pass and single backward pass during training. Our method sets a new state of the art results on two benchmarks TvSum and SumMe, commonly used in this domain.
AMNet: Memorability Estimation with Attention
Apr 09, 2018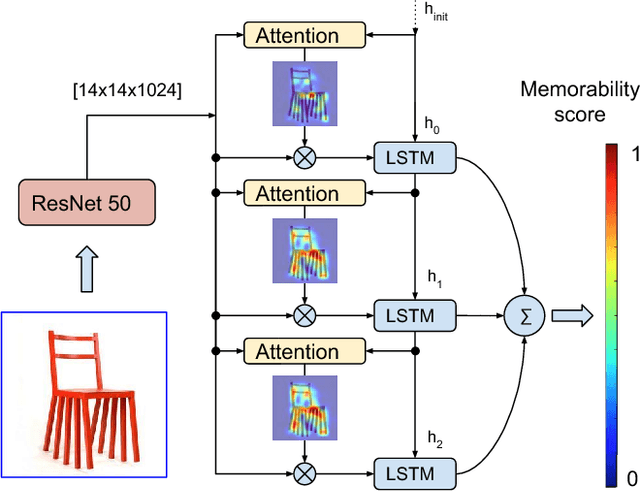
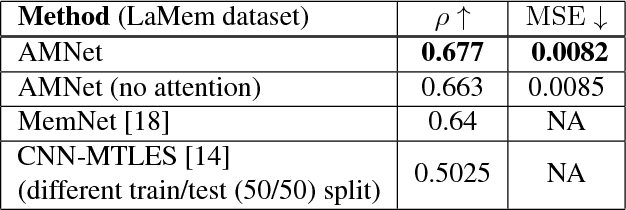
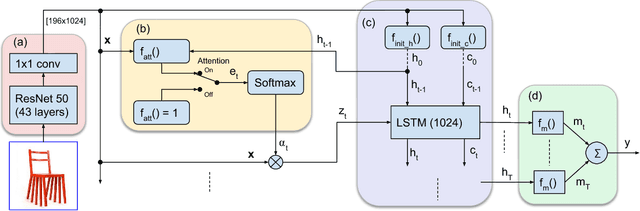
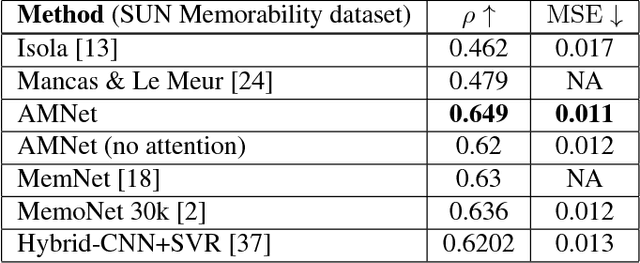
In this paper we present the design and evaluation of an end-to-end trainable, deep neural network with a visual attention mechanism for memorability estimation in still images. We analyze the suitability of transfer learning of deep models from image classification to the memorability task. Further on we study the impact of the attention mechanism on the memorability estimation and evaluate our network on the SUN Memorability and the LaMem datasets. Our network outperforms the existing state of the art models on both datasets in terms of the Spearman's rank correlation as well as the mean squared error, closely matching human consistency.