 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundational Models for Pathology and Endoscopy Images: Application for Gastric Inflammation
Jun 26, 2024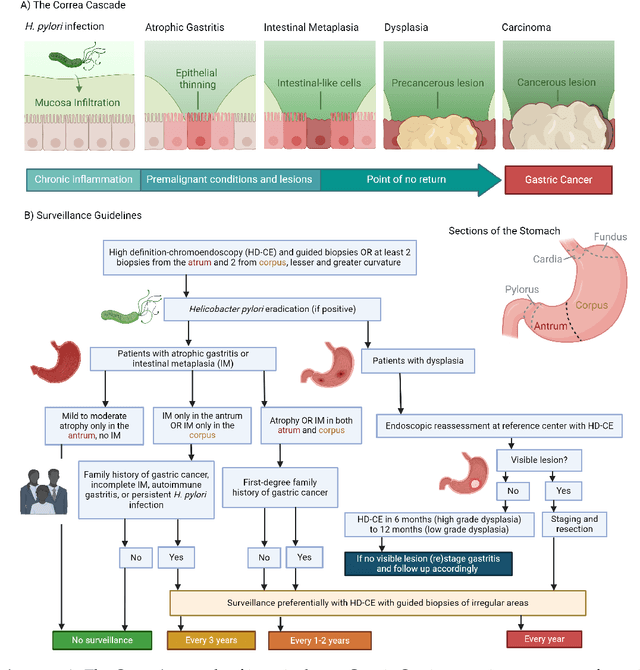
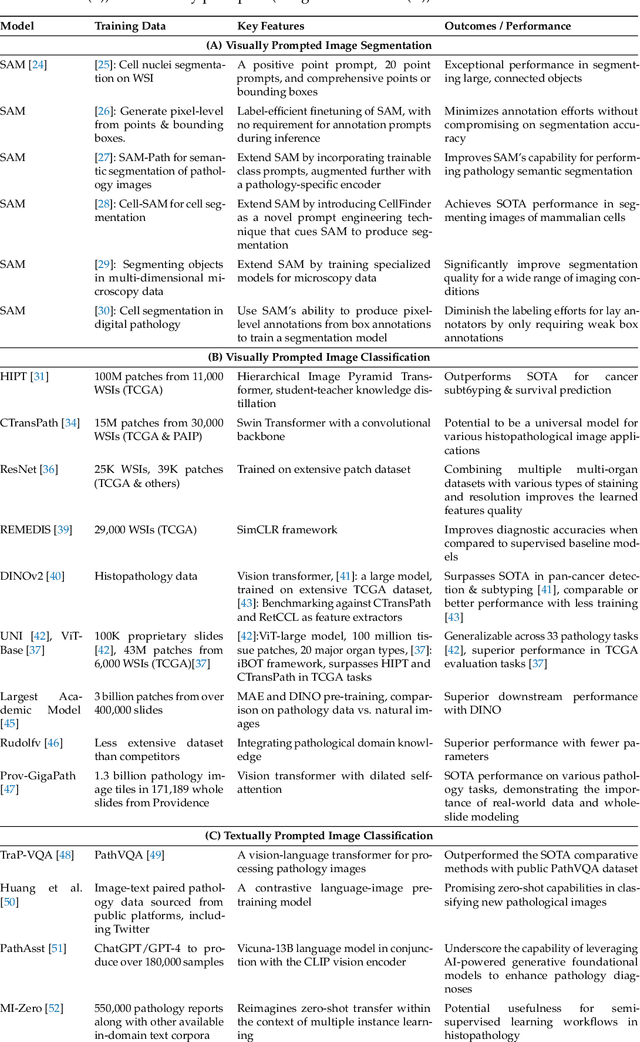
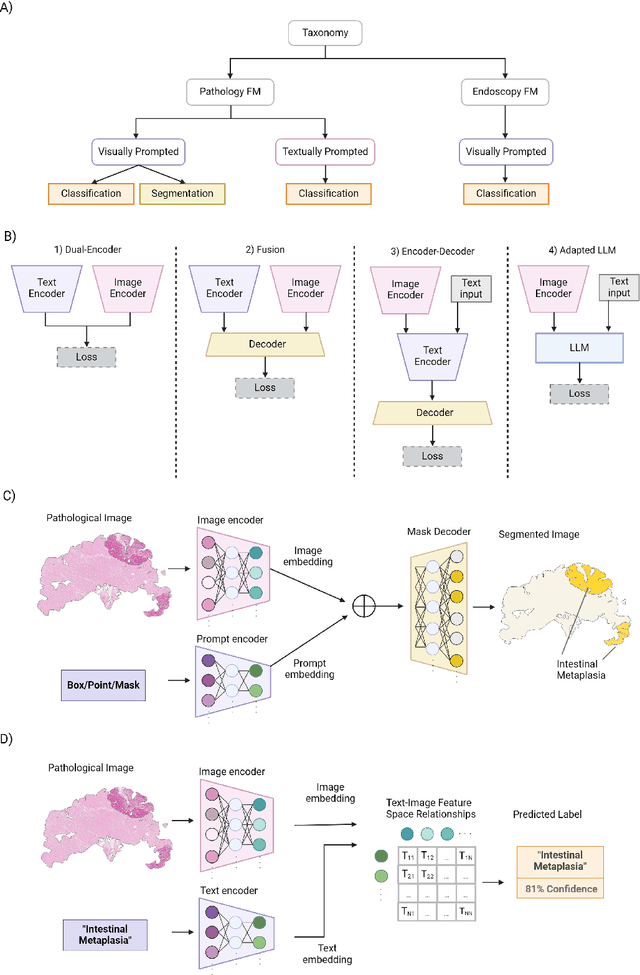
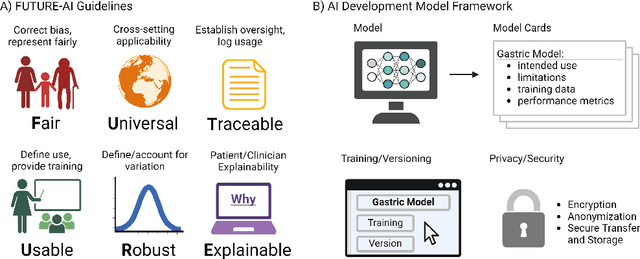
The integration of artificial intelligence (AI) in medical diagnostics represents a significant advancement in managing upper gastrointestinal (GI) cancer, a major cause of global cancer mortality. Specifically for gastric cancer (GC), chronic inflammation causes changes in the mucosa such as atrophy, intestinal metaplasia (IM), dysplasia and ultimately cancer. Early detection through endoscopic regular surveillance is essential for better outcomes. Foundation models (FM), which are machine or deep learning models trained on diverse data and applicable to broad use cases, offer a promising solution to enhance the accuracy of endoscopy and its subsequent pathology image analysis. This review explores the recent advancements, applications, and challenges associated with FM in endoscopy and pathology imaging. We started by elucidating the core principles and architectures underlying these models, including their training methodologies and the pivotal role of large-scale data in developing their predictive capabilities. Moreover, this work discusses emerging trends and future research directions, emphasizing the integration of multimodal data, the development of more robust and equitable models, and the potential for real-time diagnostic support. This review aims to provide a roadmap for researchers and practitioners in navigating the complexities of incorporating FM into clinical practice for prevention/management of GC cases, thereby improving patient outcomes.
Segmentation and Optimal Region Selection of Physiological Signals using Deep Neural Networks and Combinatorial Optimization
Mar 17, 2020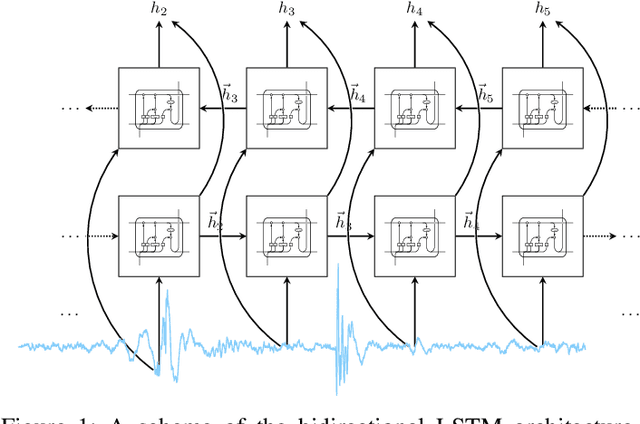
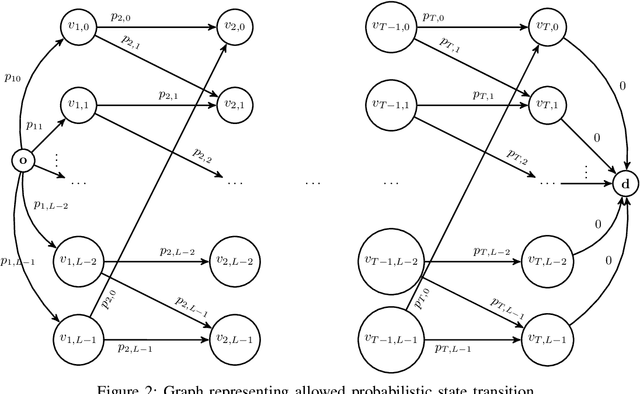
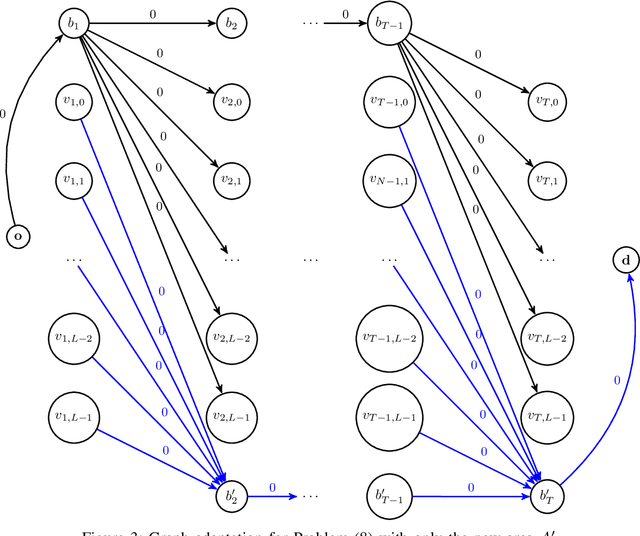
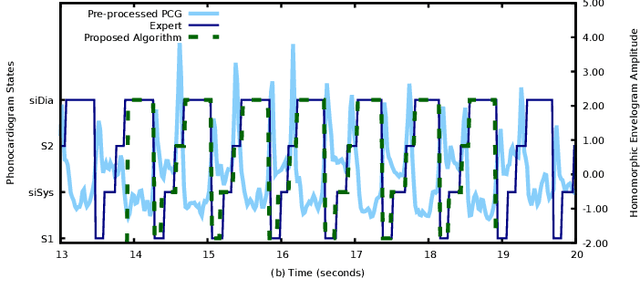
Physiological signals, such as the electrocardiogram and the phonocardiogram are very often corrupted by noisy sources. Usually, artificial intelligent algorithms analyze the signal regardless of its quality. On the other hand, physicians use a completely orthogonal strategy. They do not assess the entire recording, instead they search for a segment where the fundamental and abnormal waves are easily detected, and only then a prognostic is attempted. Inspired by this fact, a new algorithm that automatically selects an optimal segment for a post-processing stage, according to a criteria defined by the user is proposed. In the process, a Neural Network is used to compute the output state probability distribution for each sample. Using the aforementioned quantities, a graph is designed, whereas state transition constraints are physically imposed into the graph and a set of constraints are used to retrieve a subset of the recording that maximizes the likelihood function, proposed by the user. The developed framework is tested and validated in two applications. In both cases, the system performance is boosted significantly, e.g in heart sound segmentation, sensitivity increases 2.4% when compared to the standard approaches in the literature.