 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRight Regions, Wrong Labels: Semantic Label Flips in Segmentation under Correlation Shift
Apr 14, 2026The robustness of machine learning models can be compromised by spurious correlations between non-causal features in the input data and target labels. A common way to test for such correlations is to train on data where the label is strongly tied to some non-causal cue, then evaluate on examples where that tie no longer holds. This idea is well established for classification tasks, but for semantic segmentation the specific failure modes are not well understood. We show that a model may achieve reasonable overlap while assigning the wrong semantic label, swapping one plausible foreground class for another, even when object boundaries are largely correct. We focus on this semantic label-flip behaviour and quantify it with a simple diagnostic (Flip) that counts how often ground truth foreground pixels are assigned the wrong foreground identity while remaining predicted as foreground. In a setting where category and scene are correlated during training, increasing the correlation consistently widens the gap between common and rare test conditions and increases these within-object label swaps on counterfactual groups. Overall, our results motivate assessing segmentation robustness under distribution shift beyond overlap by decomposing foreground errors into correct pixels, flipped-identity pixels, and missed-to-background pixels. We also propose an entropy-based, ground truth label-free `flip-risk' score, which is computed from foreground identity uncertainty, and show that it can flag flip-prone cases at inference time. Code is available at https://github.com/acharaakshit/label-flips.
Understanding Sources of Demographic Predictability in Brain MRI via Disentangling Anatomy and Contrast
Mar 04, 2026Demographic attributes such as age, sex, and race can be predicted from medical images, raising concerns about bias in clinical AI systems. In brain MRI, this signal may arise from anatomical variation, acquisition-dependent contrast differences, or both, yet these sources remain entangled in conventional analyses. Without disentangling them, mitigation strategies risk failing to address the underlying causes. We propose a controlled framework based on disentangled representation learning, decomposing brain MRI into anatomy-focused representations that suppress acquisition influence and contrast embeddings that capture acquisition-dependent characteristics. Training predictive models for age, sex, and race on full images, anatomical representations, and contrast-only embeddings allows us to quantify the relative contributions of structure and acquisition to the demographic signal. Across three datasets and multiple MRI sequences, we find that demographic predictability is primarily rooted in anatomical variation: anatomy-focused representations largely preserve the performance of models trained on raw images. Contrast-only embeddings retain a weaker but systematic signal that is dataset-specific and does not generalise across sites. These findings suggest that effective mitigation must explicitly account for the distinct anatomical and acquisition-dependent origins of the demographic signal, ensuring that any bias reduction generalizes robustly across domains.
Multi-Way Representation Alignment
Feb 05, 2026The Platonic Representation Hypothesis suggests that independently trained neural networks converge to increasingly similar latent spaces. However, current strategies for mapping these representations are inherently pairwise, scaling quadratically with the number of models and failing to yield a consistent global reference. In this paper, we study the alignment of $M \ge 3$ models. We first adapt Generalized Procrustes Analysis (GPA) to construct a shared orthogonal universe that preserves the internal geometry essential for tasks like model stitching. We then show that strict isometric alignment is suboptimal for retrieval, where agreement-maximizing methods like Canonical Correlation Analysis (CCA) typically prevail. To bridge this gap, we finally propose Geometry-Corrected Procrustes Alignment (GCPA), which establishes a robust GPA-based universe followed by a post-hoc correction for directional mismatch. Extensive experiments demonstrate that GCPA consistently improves any-to-any retrieval while retaining a practical shared reference space.
Localising Shortcut Learning in Pixel Space via Ordinal Scoring Correlations for Attribution Representations (OSCAR)
Dec 21, 2025

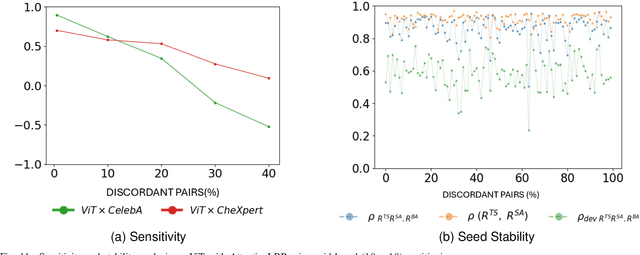

Deep neural networks often exploit shortcuts. These are spurious cues which are associated with output labels in the training data but are unrelated to task semantics. When the shortcut features are associated with sensitive attributes, shortcut learning can lead to biased model performance. Existing methods for localising and understanding shortcut learning are mostly based upon qualitative, image-level inspection and assume cues are human-visible, limiting their use in domains such as medical imaging. We introduce OSCAR (Ordinal Scoring Correlations for Attribution Representations), a model-agnostic framework for quantifying shortcut learning and localising shortcut features. OSCAR converts image-level task attribution maps into dataset-level rank profiles of image regions and compares them across three models: a balanced baseline model (BA), a test model (TS), and a sensitive attribute predictor (SA). By computing pairwise, partial, and deviation-based correlations on these rank profiles, we produce a set of quantitative metrics that characterise the degree of shortcut reliance for TS, together with a ranking of image-level regions that contribute most to it. Experiments on CelebA, CheXpert, and ADNI show that our correlations are (i) stable across seeds and partitions, (ii) sensitive to the level of association between shortcut features and output labels in the training data, and (iii) able to distinguish localised from diffuse shortcut features. As an illustration of the utility of our method, we show how worst-group performance disparities can be reduced using a simple test-time attenuation approach based on the identified shortcut regions. OSCAR provides a lightweight, pixel-space audit that yields statistical decision rules and spatial maps, enabling users to test, localise, and mitigate shortcut reliance. The code is available at https://github.com/acharaakshit/oscar
Invisible Attributes, Visible Biases: Exploring Demographic Shortcuts in MRI-based Alzheimer's Disease Classification
Sep 11, 2025Magnetic resonance imaging (MRI) is the gold standard for brain imaging. Deep learning (DL) algorithms have been proposed to aid in the diagnosis of diseases such as Alzheimer's disease (AD) from MRI scans. However, DL algorithms can suffer from shortcut learning, in which spurious features, not directly related to the output label, are used for prediction. When these features are related to protected attributes, they can lead to performance bias against underrepresented protected groups, such as those defined by race and sex. In this work, we explore the potential for shortcut learning and demographic bias in DL based AD diagnosis from MRI. We first investigate if DL algorithms can identify race or sex from 3D brain MRI scans to establish the presence or otherwise of race and sex based distributional shifts. Next, we investigate whether training set imbalance by race or sex can cause a drop in model performance, indicating shortcut learning and bias. Finally, we conduct a quantitative and qualitative analysis of feature attributions in different brain regions for both the protected attribute and AD classification tasks. Through these experiments, and using multiple datasets and DL models (ResNet and SwinTransformer), we demonstrate the existence of both race and sex based shortcut learning and bias in DL based AD classification. Our work lays the foundation for fairer DL diagnostic tools in brain MRI. The code is provided at https://github.com/acharaakshit/ShortMR
Efficient Biomedical Entity Linking: Clinical Text Standardization with Low-Resource Techniques
May 27, 2024Clinical text is rich in information, with mentions of treatment, medication and anatomy among many other clinical terms. Multiple terms can refer to the same core concepts which can be referred as a clinical entity. Ontologies like the Unified Medical Language System (UMLS) are developed and maintained to store millions of clinical entities including the definitions, relations and other corresponding information. These ontologies are used for standardization of clinical text by normalizing varying surface forms of a clinical term through Biomedical entity linking. With the introduction of transformer-based language models, there has been significant progress in Biomedical entity linking. In this work, we focus on learning through synonym pairs associated with the entities. As compared to the existing approaches, our approach significantly reduces the training data and resource consumption. Moreover, we propose a suite of context-based and context-less reranking techniques for performing the entity disambiguation. Overall, we achieve similar performance to the state-of-the-art zero-shot and distant supervised entity linking techniques on the Medmentions dataset, the largest annotated dataset on UMLS, without any domain-based training. Finally, we show that retrieval performance alone might not be sufficient as an evaluation metric and introduce an article level quantitative and qualitative analysis to reveal further insights on the performance of entity linking methods.
Revealing the Underlying Patterns: Investigating Dataset Similarity, Performance, and Generalization
Aug 26, 2023Supervised deep learning models require significant amount of labelled data to achieve an acceptable performance on a specific task. However, when tested on unseen data, the models may not perform well. Therefore, the models need to be trained with additional and varying labelled data to improve the generalization. In this work, our goal is to understand the models, their performance and generalization. We establish image-image, dataset-dataset, and image-dataset distances to gain insights into the model's behavior. Our proposed distance metric when combined with model performance can help in selecting an appropriate model/architecture from a pool of candidate architectures. We have shown that the generalization of these models can be improved by only adding a small number of unseen images (say 1, 3 or 7) into the training set. Our proposed approach reduces training and annotation costs while providing an estimate of model performance on unseen data in dynamic environments.
TrueDeep: A systematic approach of crack detection with less data
May 30, 2023Supervised and semi-supervised semantic segmentation algorithms require significant amount of annotated data to achieve a good performance. In many situations, the data is either not available or the annotation is expensive. The objective of this work is to show that by incorporating domain knowledge along with deep learning architectures, we can achieve similar performance with less data. We have used publicly available crack segmentation datasets and shown that selecting the input images using knowledge can significantly boost the performance of deep-learning based architectures. Our proposed approaches have many fold advantages such as low annotation and training cost, and less energy consumption. We have measured the performance of our algorithm quantitatively in terms of mean intersection over union (mIoU) and F score. Our algorithms, developed with 23% of the overall data; have a similar performance on the test data and significantly better performance on multiple blind datasets.
CoreDeep: Improving Crack Detection Algorithms Using Width Stochasticity
Sep 10, 2022
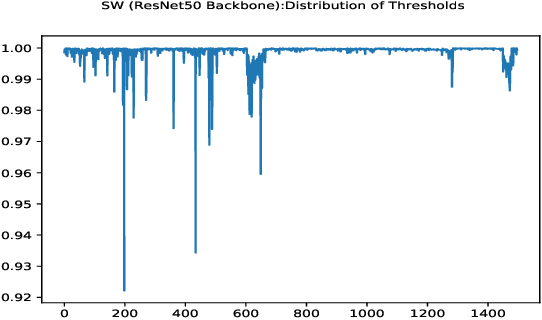


Automatically detecting or segmenting cracks in images can help in reducing the cost of maintenance or operations. Detecting, measuring and quantifying cracks for distress analysis in challenging background scenarios is a difficult task as there is no clear boundary that separates cracks from the background. Developed algorithms should handle the inherent challenges associated with data. Some of the perceptually noted challenges are color, intensity, depth, blur, motion-blur, orientation, different region of interest (ROI) for the defect, scale, illumination, complex and challenging background, etc. These variations occur across (crack inter class) and within images (crack intra-class variabilities). Overall, there is significant background (inter) and foreground (intra-class) variability. In this work, we have attempted to reduce the effect of these variations in challenging background scenarios. We have proposed a stochastic width (SW) approach to reduce the effect of these variations. Our proposed approach improves detectability and significantly reduces false positives and negatives. We have measured the performance of our algorithm objectively in terms of mean IoU, false positives and negatives and subjectively in terms of perceptual quality.