 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Biomedical Entity Linking: Clinical Text Standardization with Low-Resource Techniques
May 27, 2024Clinical text is rich in information, with mentions of treatment, medication and anatomy among many other clinical terms. Multiple terms can refer to the same core concepts which can be referred as a clinical entity. Ontologies like the Unified Medical Language System (UMLS) are developed and maintained to store millions of clinical entities including the definitions, relations and other corresponding information. These ontologies are used for standardization of clinical text by normalizing varying surface forms of a clinical term through Biomedical entity linking. With the introduction of transformer-based language models, there has been significant progress in Biomedical entity linking. In this work, we focus on learning through synonym pairs associated with the entities. As compared to the existing approaches, our approach significantly reduces the training data and resource consumption. Moreover, we propose a suite of context-based and context-less reranking techniques for performing the entity disambiguation. Overall, we achieve similar performance to the state-of-the-art zero-shot and distant supervised entity linking techniques on the Medmentions dataset, the largest annotated dataset on UMLS, without any domain-based training. Finally, we show that retrieval performance alone might not be sufficient as an evaluation metric and introduce an article level quantitative and qualitative analysis to reveal further insights on the performance of entity linking methods.
Double Ramp Loss Based Reject Option Classifier
Dec 08, 2014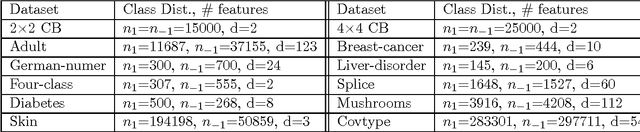
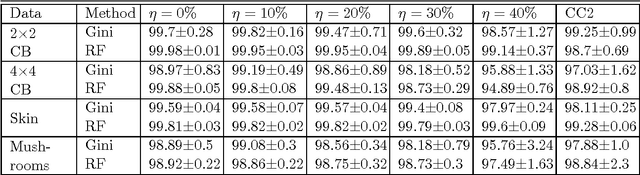
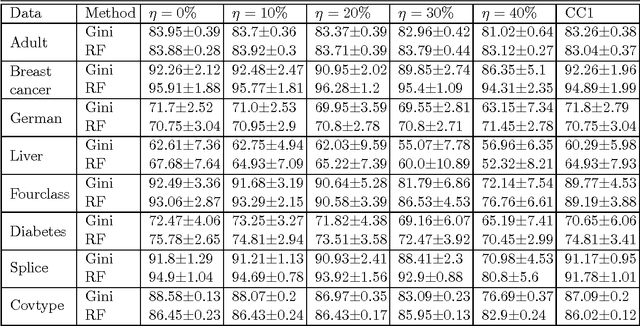
We consider the problem of learning reject option classifiers. The goodness of a reject option classifier is quantified using $0-d-1$ loss function wherein a loss $d \in (0,.5)$ is assigned for rejection. In this paper, we propose {\em double ramp loss} function which gives a continuous upper bound for $(0-d-1)$ loss. Our approach is based on minimizing regularized risk under the double ramp loss using {\em difference of convex (DC) programming}. We show the effectiveness of our approach through experiments on synthetic and benchmark datasets. Our approach performs better than the state of the art reject option classification approaches.