 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Taming Diffusion for in-the-wild Video Amodal Completion
Mar 15, 2025Humans can infer complete shapes and appearances of objects from limited visual cues, relying on extensive prior knowledge of the physical world. However, completing partially observable objects while ensuring consistency across video frames remains challenging for existing models, especially for unstructured, in-the-wild videos. This paper tackles the task of Video Amodal Completion (VAC), which aims to generate the complete object consistently throughout the video given a visual prompt specifying the object of interest. Leveraging the rich, consistent manifolds learned by pre-trained video diffusion models, we propose a conditional diffusion model, TACO, that repurposes these manifolds for VAC. To enable its effective and robust generalization to challenging in-the-wild scenarios, we curate a large-scale synthetic dataset with multiple difficulty levels by systematically imposing occlusions onto un-occluded videos. Building on this, we devise a progressive fine-tuning paradigm that starts with simpler recovery tasks and gradually advances to more complex ones. We demonstrate TACO's versatility on a wide range of in-the-wild videos from Internet, as well as on diverse, unseen datasets commonly used in autonomous driving, robotic manipulation, and scene understanding. Moreover, we show that TACO can be effectively applied to various downstream tasks like object reconstruction and pose estimation, highlighting its potential to facilitate physical world understanding and reasoning. Our project page is available at https://jason-aplp.github.io/TACO.
MOVIS: Enhancing Multi-Object Novel View Synthesis for Indoor Scenes
Dec 16, 2024



Repurposing pre-trained diffusion models has been proven to be effective for NVS. However, these methods are mostly limited to a single object; directly applying such methods to compositional multi-object scenarios yields inferior results, especially incorrect object placement and inconsistent shape and appearance under novel views. How to enhance and systematically evaluate the cross-view consistency of such models remains under-explored. To address this issue, we propose MOVIS to enhance the structural awareness of the view-conditioned diffusion model for multi-object NVS in terms of model inputs, auxiliary tasks, and training strategy. First, we inject structure-aware features, including depth and object mask, into the denoising U-Net to enhance the model's comprehension of object instances and their spatial relationships. Second, we introduce an auxiliary task requiring the model to simultaneously predict novel view object masks, further improving the model's capability in differentiating and placing objects. Finally, we conduct an in-depth analysis of the diffusion sampling process and carefully devise a structure-guided timestep sampling scheduler during training, which balances the learning of global object placement and fine-grained detail recovery. To systematically evaluate the plausibility of synthesized images, we propose to assess cross-view consistency and novel view object placement alongside existing image-level NVS metrics. Extensive experiments on challenging synthetic and realistic datasets demonstrate that our method exhibits strong generalization capabilities and produces consistent novel view synthesis, highlighting its potential to guide future 3D-aware multi-object NVS tasks.
Template-free Articulated Gaussian Splatting for Real-time Reposable Dynamic View Synthesis
Dec 07, 2024While novel view synthesis for dynamic scenes has made significant progress, capturing skeleton models of objects and re-posing them remains a challenging task. To tackle this problem, in this paper, we propose a novel approach to automatically discover the associated skeleton model for dynamic objects from videos without the need for object-specific templates. Our approach utilizes 3D Gaussian Splatting and superpoints to reconstruct dynamic objects. Treating superpoints as rigid parts, we can discover the underlying skeleton model through intuitive cues and optimize it using the kinematic model. Besides, an adaptive control strategy is applied to avoid the emergence of redundant superpoints. Extensive experiments demonstrate the effectiveness and efficiency of our method in obtaining re-posable 3D objects. Not only can our approach achieve excellent visual fidelity, but it also allows for the real-time rendering of high-resolution images.
Superpoint Gaussian Splatting for Real-Time High-Fidelity Dynamic Scene Reconstruction
Jun 06, 2024Rendering novel view images in dynamic scenes is a crucial yet challenging task. Current methods mainly utilize NeRF-based methods to represent the static scene and an additional time-variant MLP to model scene deformations, resulting in relatively low rendering quality as well as slow inference speed. To tackle these challenges, we propose a novel framework named Superpoint Gaussian Splatting (SP-GS). Specifically, our framework first employs explicit 3D Gaussians to reconstruct the scene and then clusters Gaussians with similar properties (e.g., rotation, translation, and location) into superpoints. Empowered by these superpoints, our method manages to extend 3D Gaussian splatting to dynamic scenes with only a slight increase in computational expense. Apart from achieving state-of-the-art visual quality and real-time rendering under high resolutions, the superpoint representation provides a stronger manipulation capability. Extensive experiments demonstrate the practicality and effectiveness of our approach on both synthetic and real-world datasets. Please see our project page at https://dnvtmf.github.io/SP_GS.github.io.
Interactive Segment Anything NeRF with Feature Imitation
May 25, 2023



This paper investigates the potential of enhancing Neural Radiance Fields (NeRF) with semantics to expand their applications. Although NeRF has been proven useful in real-world applications like VR and digital creation, the lack of semantics hinders interaction with objects in complex scenes. We propose to imitate the backbone feature of off-the-shelf perception models to achieve zero-shot semantic segmentation with NeRF. Our framework reformulates the segmentation process by directly rendering semantic features and only applying the decoder from perception models. This eliminates the need for expensive backbones and benefits 3D consistency. Furthermore, we can project the learned semantics onto extracted mesh surfaces for real-time interaction. With the state-of-the-art Segment Anything Model (SAM), our framework accelerates segmentation by 16 times with comparable mask quality. The experimental results demonstrate the efficacy and computational advantages of our approach. Project page: \url{https://me.kiui.moe/san/}.
Controllable Orthogonalization in Training DNNs
Apr 02, 2020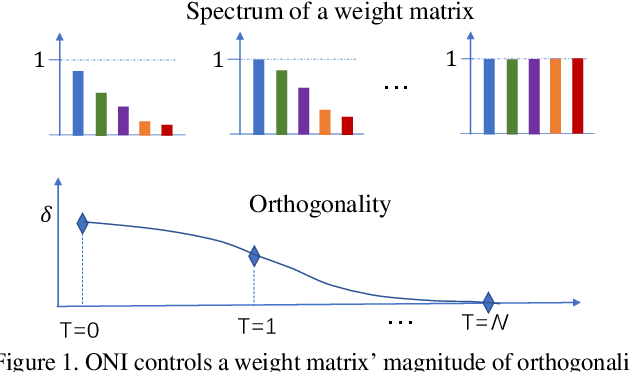
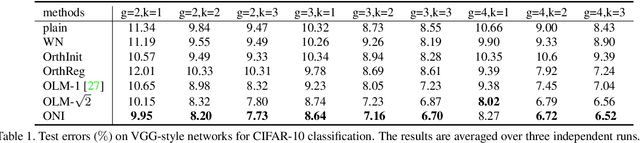
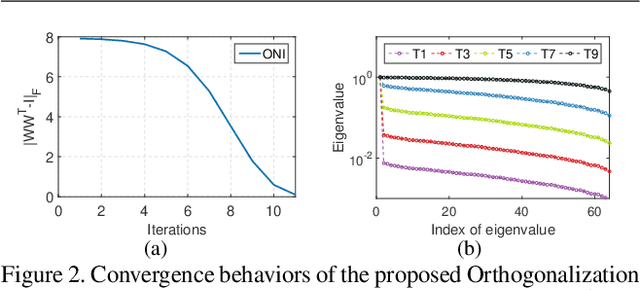

Orthogonality is widely used for training deep neural networks (DNNs) due to its ability to maintain all singular values of the Jacobian close to 1 and reduce redundancy in representation. This paper proposes a computationally efficient and numerically stable orthogonalization method using Newton's iteration (ONI), to learn a layer-wise orthogonal weight matrix in DNNs. ONI works by iteratively stretching the singular values of a weight matrix towards 1. This property enables it to control the orthogonality of a weight matrix by its number of iterations. We show that our method improves the performance of image classification networks by effectively controlling the orthogonality to provide an optimal tradeoff between optimization benefits and representational capacity reduction. We also show that ONI stabilizes the training of generative adversarial networks (GANs) by maintaining the Lipschitz continuity of a network, similar to spectral normalization (SN), and further outperforms SN by providing controllable orthogonality.