 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradeADreamer: Enhanced Text-to-3D Generation Using Gaussian Splatting and Multi-View Diffusion
Jun 14, 2024



Text-to-3D generation has shown promising results, yet common challenges such as the Multi-face Janus problem and extended generation time for high-quality assets. In this paper, we address these issues by introducing a novel three-stage training pipeline called GradeADreamer. This pipeline is capable of producing high-quality assets with a total generation time of under 30 minutes using only a single RTX 3090 GPU. Our proposed method employs a Multi-view Diffusion Model, MVDream, to generate Gaussian Splats as a prior, followed by refining geometry and texture using StableDiffusion. Experimental results demonstrate that our approach significantly mitigates the Multi-face Janus problem and achieves the highest average user preference ranking compared to previous state-of-the-art methods. The project code is available at https://github.com/trapoom555/GradeADreamer.
Exploring Text-to-Motion Generation with Human Preference
Apr 15, 2024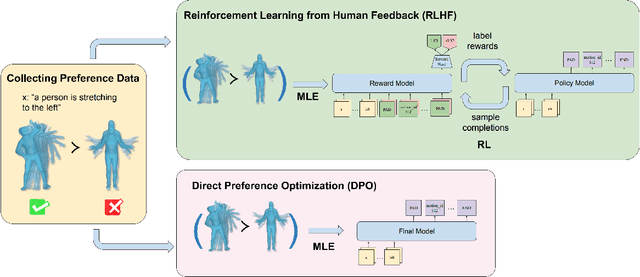

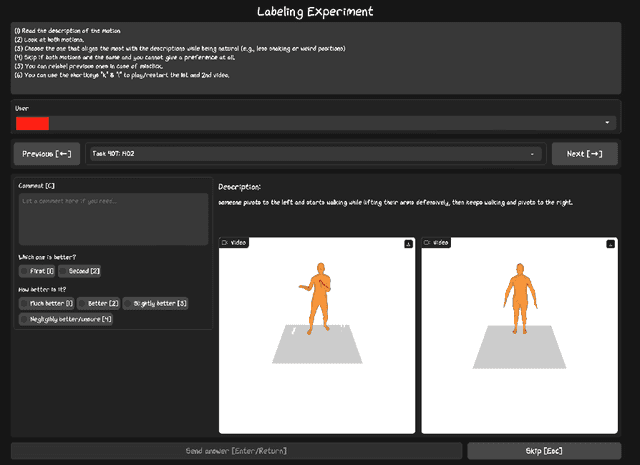

This paper presents an exploration of preference learning in text-to-motion generation. We find that current improvements in text-to-motion generation still rely on datasets requiring expert labelers with motion capture systems. Instead, learning from human preference data does not require motion capture systems; a labeler with no expertise simply compares two generated motions. This is particularly efficient because evaluating the model's output is easier than gathering the motion that performs a desired task (e.g. backflip). To pioneer the exploration of this paradigm, we annotate 3,528 preference pairs generated by MotionGPT, marking the first effort to investigate various algorithms for learning from preference data. In particular, our exploration highlights important design choices when using preference data. Additionally, our experimental results show that preference learning has the potential to greatly improve current text-to-motion generative models. Our code and dataset are publicly available at https://github.com/THU-LYJ-Lab/InstructMotion}{https://github.com/THU-LYJ-Lab/InstructMotion to further facilitate research in this area.