 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Self-Supervised Pre-Training Performs with Streaming Data?
Apr 25, 2021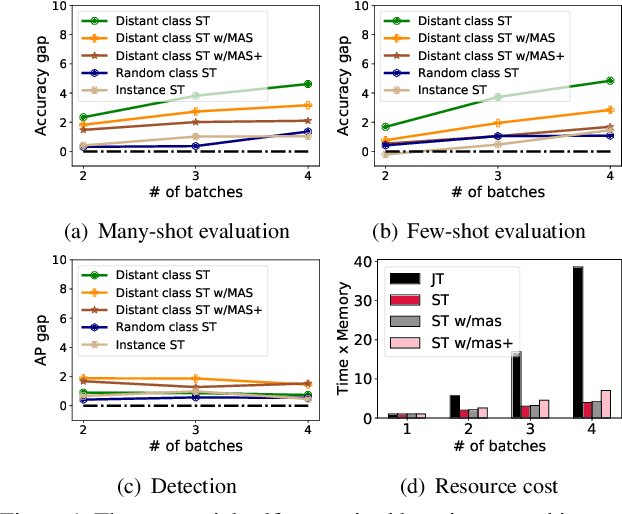
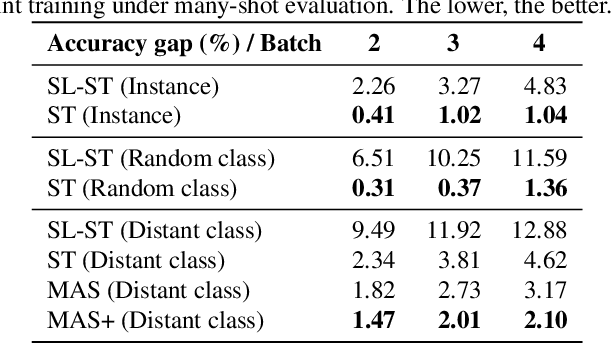
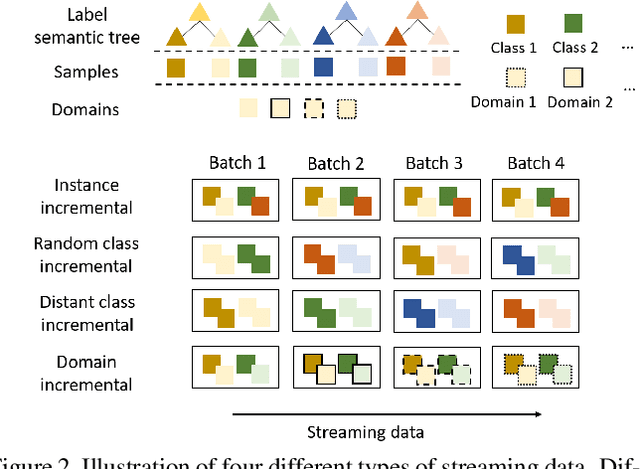
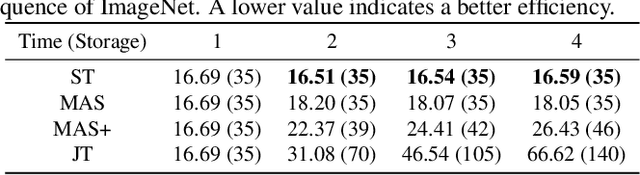
The common self-supervised pre-training practice requires collecting massive unlabeled data together and then trains a representation model, dubbed \textbf{joint training}. However, in real-world scenarios where data are collected in a streaming fashion, the joint training scheme is usually storage-heavy and time-consuming. A more efficient alternative is to train a model continually with streaming data, dubbed \textbf{sequential training}. Nevertheless, it is unclear how well sequential self-supervised pre-training performs with streaming data. In this paper, we conduct thorough experiments to investigate self-supervised pre-training with streaming data. Specifically, we evaluate the transfer performance of sequential self-supervised pre-training with four different data sequences on three different downstream tasks and make comparisons with joint self-supervised pre-training. Surprisingly, we find sequential self-supervised learning exhibits almost the same performance as the joint training when the distribution shifts within streaming data are mild. Even for data sequences with large distribution shifts, sequential self-supervised training with simple techniques, e.g., parameter regularization or data replay, still performs comparably to joint training. Based on our findings, we recommend using sequential self-supervised training as a \textbf{more efficient yet performance-competitive} representation learning practice for real-world applications.