 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Sparse Attention: Combining Computational Efficiency with Training Stability for Long-Context Language Models
Jan 12, 2026The computational burden of attention in long-context language models has motivated two largely independent lines of work: sparse attention mechanisms that reduce complexity by attending to selected tokens, and gated attention variants that improve training sta-bility while mitigating the attention sink phenomenon. We observe that these approaches address complementary weaknesses and propose Gated Sparse Attention (GSA), an architecture that realizes the benefits of both. GSA incorporates a gated lightning indexer with sigmoid activations that produce bounded, interpretable selection scores, an adaptive sparsity controller that modulates the number of attended tokens based on local uncertainty, and dual gating at the value and output stages. We establish theoretical foundations for the approach, including complexity analysis, expressiveness results, and convergence guarantees. In experiments with 1.7B parameter models trained on 400B tokens, GSA matches the efficiency of sparse-only baselines (12-16x speedup at 128K context) while achieving the quality gains associated with gated attention: perplexity improves from 6.03 to 5.70, RULER scores at 128K context nearly double, and attention to the first token, a proxy for attention sinks, drops from 47% to under 4%. Training stability improves markedly, with loss spikes reduced by 98%.
How Well Self-Supervised Pre-Training Performs with Streaming Data?
Apr 25, 2021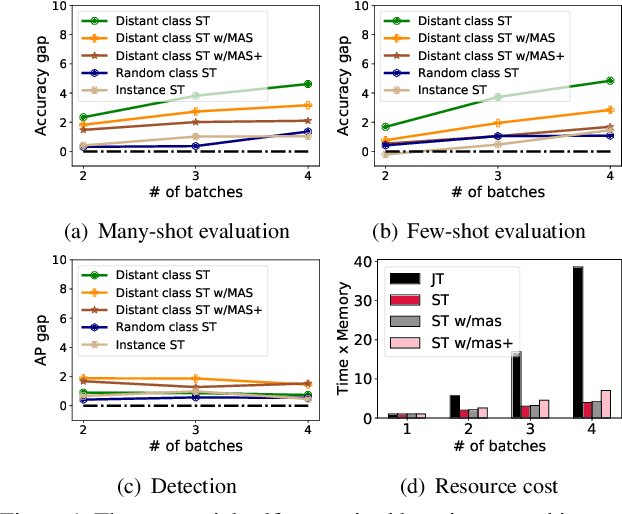
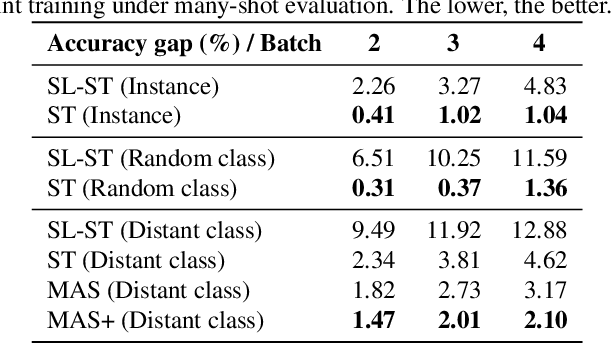
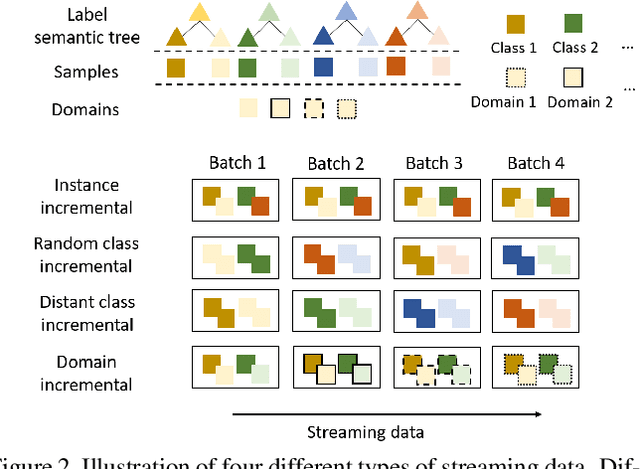
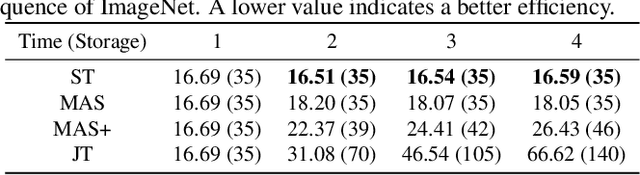
The common self-supervised pre-training practice requires collecting massive unlabeled data together and then trains a representation model, dubbed \textbf{joint training}. However, in real-world scenarios where data are collected in a streaming fashion, the joint training scheme is usually storage-heavy and time-consuming. A more efficient alternative is to train a model continually with streaming data, dubbed \textbf{sequential training}. Nevertheless, it is unclear how well sequential self-supervised pre-training performs with streaming data. In this paper, we conduct thorough experiments to investigate self-supervised pre-training with streaming data. Specifically, we evaluate the transfer performance of sequential self-supervised pre-training with four different data sequences on three different downstream tasks and make comparisons with joint self-supervised pre-training. Surprisingly, we find sequential self-supervised learning exhibits almost the same performance as the joint training when the distribution shifts within streaming data are mild. Even for data sequences with large distribution shifts, sequential self-supervised training with simple techniques, e.g., parameter regularization or data replay, still performs comparably to joint training. Based on our findings, we recommend using sequential self-supervised training as a \textbf{more efficient yet performance-competitive} representation learning practice for real-world applications.