 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimate AI for Corporate Decarbonization Metrics Extraction
Nov 05, 2024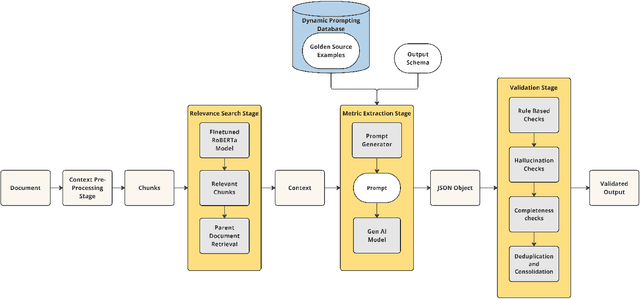

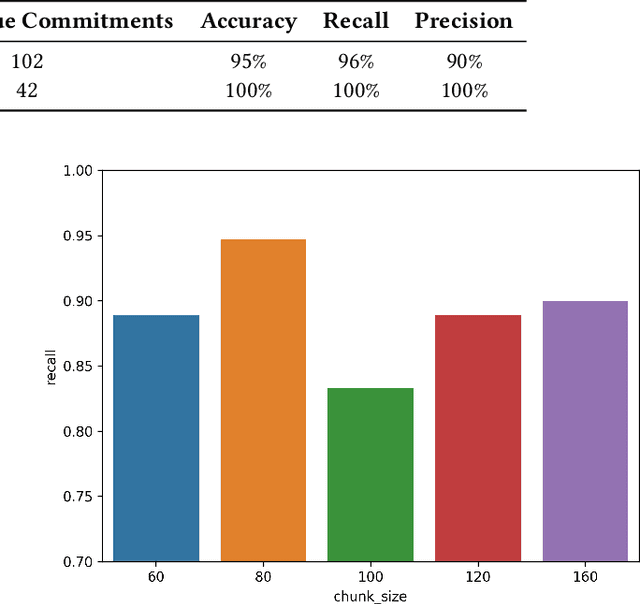

Corporate Greenhouse Gas (GHG) emission targets are important metrics in sustainable investing [12, 16]. To provide a comprehensive view of company emission objectives, we propose an approach to source these metrics from company public disclosures. Without automation, curating these metrics manually is a labor-intensive process that requires combing through lengthy corporate sustainability disclosures that often do not follow a standard format. Furthermore, the resulting dataset needs to be validated thoroughly by Subject Matter Experts (SMEs), further lengthening the time-to-market. We introduce the Climate Artificial Intelligence for Corporate Decarbonization Metrics Extraction (CAI) model and pipeline, a novel approach utilizing Large Language Models (LLMs) to extract and validate linked metrics from corporate disclosures. We demonstrate that the process improves data collection efficiency and accuracy by automating data curation, validation, and metric scoring from public corporate disclosures. We further show that our results are agnostic to the choice of LLMs. This framework can be applied broadly to information extraction from textual data.
Safe Merging in Mixed Traffic with Confidence
Mar 09, 2024In this letter, we present an approach for learning human driving behavior, without relying on specific model structures or prior distributions, in a mixed-traffic environment where connected and automated vehicles (CAVs) coexist with human-driven vehicles (HDVs). We employ conformal prediction to obtain theoretical safety guarantees and use real-world traffic data to validate our approach. Then, we design a controller that ensures effective merging of CAVs with HDVs with safety guarantees. We provide numerical simulations to illustrate the efficacy of the control approach.
A Framework for Effective AI Recommendations in Cyber-Physical-Human Systems
Mar 08, 2024Many cyber-physical-human systems (CPHS) involve a human decision-maker who may receive recommendations from an artificial intelligence (AI) platform while holding the ultimate responsibility of making decisions. In such CPHS applications, the human decision-maker may depart from an optimal recommended decision and instead implement a different one for various reasons. In this letter, we develop a rigorous framework to overcome this challenge. In our framework, we consider that humans may deviate from AI recommendations as they perceive and interpret the system's state in a different way than the AI platform. We establish the structural properties of optimal recommendation strategies and develop an approximate human model (AHM) used by the AI. We provide theoretical bounds on the optimality gap that arises from an AHM and illustrate the efficacy of our results in a numerical example.
A Q-learning Approach for Adherence-Aware Recommendations
Sep 12, 2023



In many real-world scenarios involving high-stakes and safety implications, a human decision-maker (HDM) may receive recommendations from an artificial intelligence while holding the ultimate responsibility of making decisions. In this letter, we develop an "adherence-aware Q-learning" algorithm to address this problem. The algorithm learns the "adherence level" that captures the frequency with which an HDM follows the recommended actions and derives the best recommendation policy in real time. We prove the convergence of the proposed Q-learning algorithm to the optimal value and evaluate its performance across various scenarios.
Connected and Automated Vehicles in Mixed-Traffic: Learning Human Driver Behavior for Effective On-Ramp Merging
Apr 01, 2023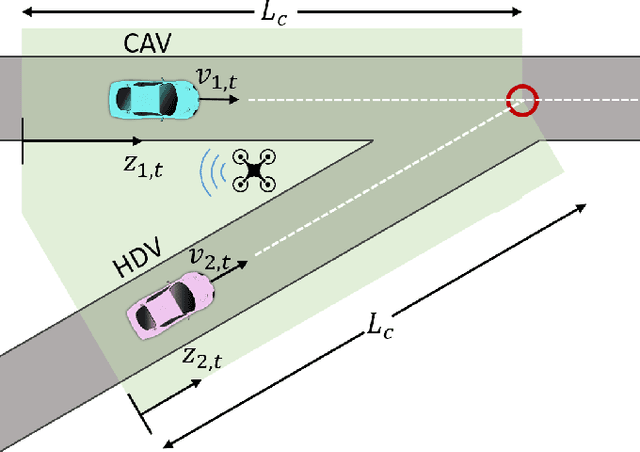
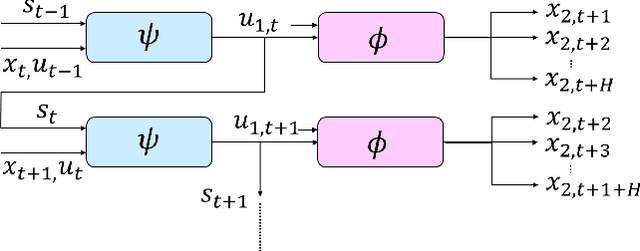
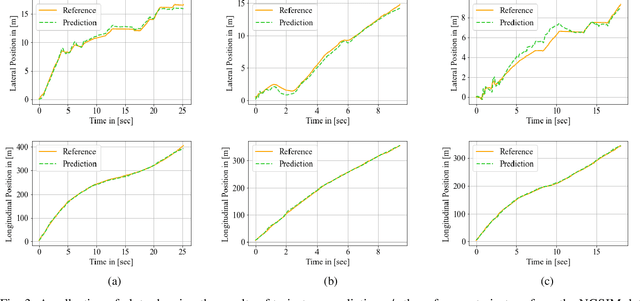
Highway merging scenarios featuring mixed traffic conditions pose significant modeling and control challenges for connected and automated vehicles (CAVs) interacting with incoming on-ramp human-driven vehicles (HDVs). In this paper, we present an approach to learn an approximate information state model of CAV-HDV interactions for a CAV to maneuver safely during highway merging. In our approach, the CAV learns the behavior of an incoming HDV using approximate information states before generating a control strategy to facilitate merging. First, we validate the efficacy of this framework on real-world data by using it to predict the behavior of an HDV in mixed traffic situations extracted from the Next-Generation Simulation repository. Then, we generate simulation data for HDV-CAV interactions in a highway merging scenario using a standard inverse reinforcement learning approach. Without assuming a prior knowledge of the generating model, we show that our approximate information state model learns to predict the future trajectory of the HDV using only observations. Subsequently, we generate safe control policies for a CAV while merging with HDVs, demonstrating a spectrum of driving behaviors, from aggressive to conservative. We demonstrate the effectiveness of the proposed approach by performing numerical simulations.
Worst-Case Control and Learning Using Partial Observations Over an Infinite Time-Horizon
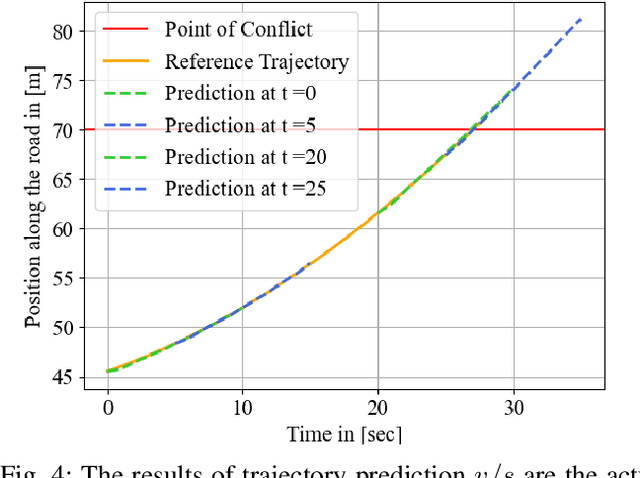
Mar 31, 2023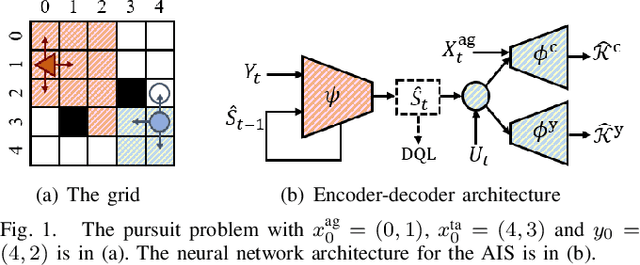
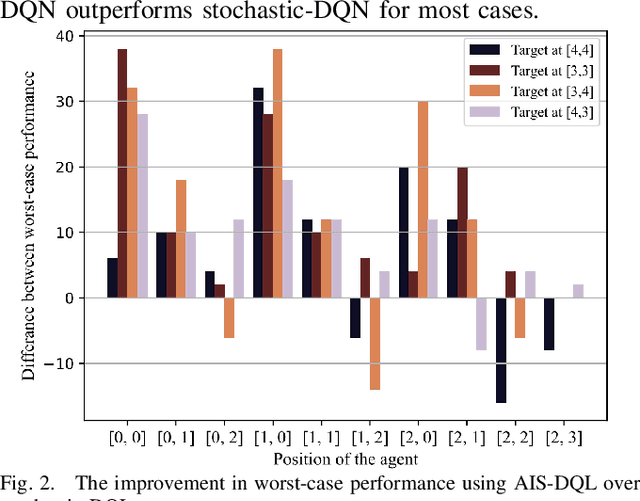
Safety-critical cyber-physical systems require control strategies whose worst-case performance is robust against adversarial disturbances and modeling uncertainties. In this paper, we present a framework for approximate control and learning in partially observed systems to minimize the worst-case discounted cost over an infinite time horizon. We model disturbances to the system as finite-valued uncertain variables with unknown probability distributions. For problems with known system dynamics, we construct a dynamic programming (DP) decomposition to compute the optimal control strategy. Our first contribution is to define information states that improve the computational tractability of this DP without loss of optimality. Then, we describe a simplification for a class of problems where the incurred cost is observable at each time instance. Our second contribution is defining an approximate information state that can be constructed or learned directly from observed data for problems with observable costs. We derive bounds on the performance loss of the resulting approximate control strategy and illustrate the effectiveness of our approach in partially observed decision-making problems with a numerical example.
Approximate Information States for Worst-Case Control and Learning in Uncertain Systems
Jan 12, 2023



In this paper, we investigate discrete-time decision-making problems in uncertain systems with partially observed states. We consider a non-stochastic model, where uncontrolled disturbances acting on the system take values in bounded sets with unknown distributions. We present a general framework for decision-making in such problems by developing the notions of information states and approximate information states. In our definition of an information state, we introduce conditions to identify for an uncertain variable sufficient to construct a dynamic program (DP) that computes an optimal strategy. We show that many information states from the literature on worst-case control actions, e.g., the conditional range, are examples of our more general definition. Next, we relax these conditions to define approximate information states using only output variables, which can be learned from output data without knowledge of system dynamics. We use this notion to formulate an approximate DP that yields a strategy with a bounded performance loss. Finally, we illustrate the application of our results in control and reinforcement learning using numerical examples.