 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill and Fine-tune: Effective Adaptation from a Black-box Source Model
Paper and Code
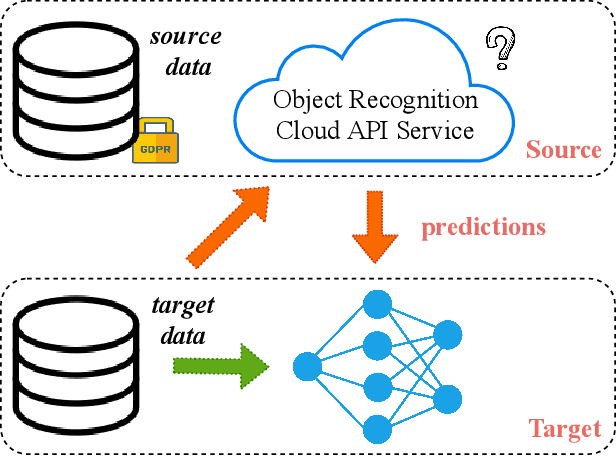
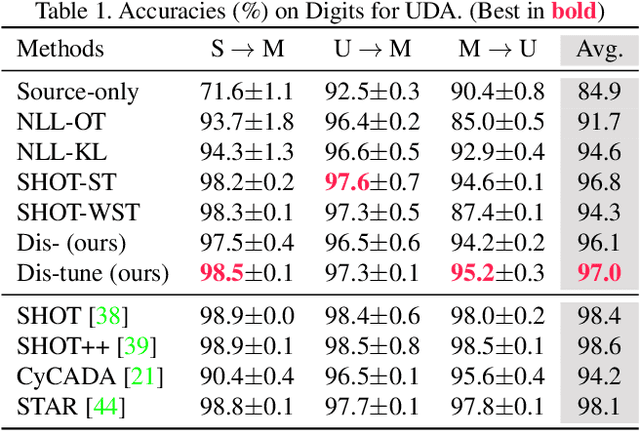
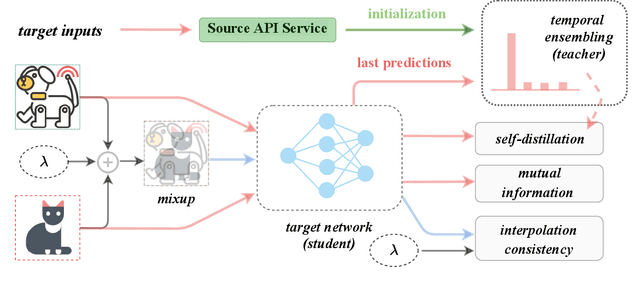
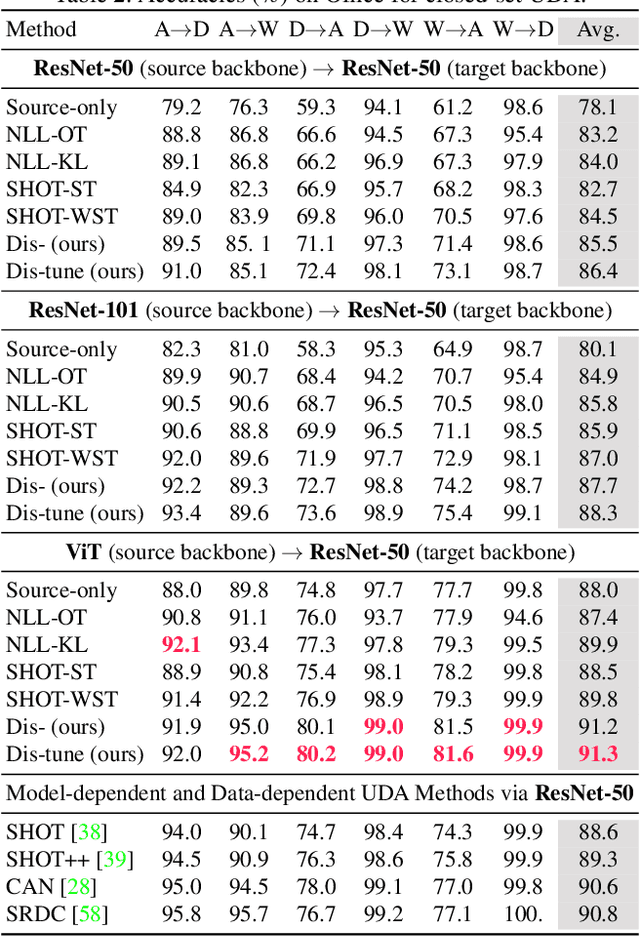
To alleviate the burden of labeling, unsupervised domain adaptation (UDA) aims to transfer knowledge in previous related labeled datasets (source) to a new unlabeled dataset (target). Despite impressive progress, prior methods always need to access the raw source data and develop data-dependent alignment approaches to recognize the target samples in a transductive learning manner, which may raise privacy concerns from source individuals. Several recent studies resort to an alternative solution by exploiting the well-trained white-box model instead of the raw data from the source domain, however, it may leak the raw data through generative adversarial training. This paper studies a practical and interesting setting for UDA, where only a black-box source model (i.e., only network predictions are available) is provided during adaptation in the target domain. Besides, different neural networks are even allowed to be employed for different domains. For this new problem, we propose a novel two-step adaptation framework called Distill and Fine-tune (Dis-tune). Specifically, Dis-tune first structurally distills the knowledge from the source model to a customized target model, then unsupervisedly fine-tunes the distilled model to fit the target domain. To verify the effectiveness, we consider two UDA scenarios (\ie, closed-set and partial-set), and discover that Dis-tune achieves highly competitive performance to state-of-the-art approaches.