 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Aug 17, 2024


Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Style-Talker: Finetuning Audio Language Model and Style-Based Text-to-Speech Model for Fast Spoken Dialogue Generation
Aug 13, 2024The rapid advancement of large language models (LLMs) has significantly propelled the development of text-based chatbots, demonstrating their capability to engage in coherent and contextually relevant dialogues. However, extending these advancements to enable end-to-end speech-to-speech conversation bots remains a formidable challenge, primarily due to the extensive dataset and computational resources required. The conventional approach of cascading automatic speech recognition (ASR), LLM, and text-to-speech (TTS) models in a pipeline, while effective, suffers from unnatural prosody because it lacks direct interactions between the input audio and its transcribed text and the output audio. These systems are also limited by their inherent latency from the ASR process for real-time applications. This paper introduces Style-Talker, an innovative framework that fine-tunes an audio LLM alongside a style-based TTS model for fast spoken dialog generation. Style-Talker takes user input audio and uses transcribed chat history and speech styles to generate both the speaking style and text for the response. Subsequently, the TTS model synthesizes the speech, which is then played back to the user. While the response speech is being played, the input speech undergoes ASR processing to extract the transcription and speaking style, serving as the context for the ensuing dialogue turn. This novel pipeline accelerates the traditional cascade ASR-LLM-TTS systems while integrating rich paralinguistic information from input speech. Our experimental results show that Style-Talker significantly outperforms the conventional cascade and speech-to-speech baselines in terms of both dialogue naturalness and coherence while being more than 50% faster.
Music Source Separation with Generative Flow
Apr 26, 2022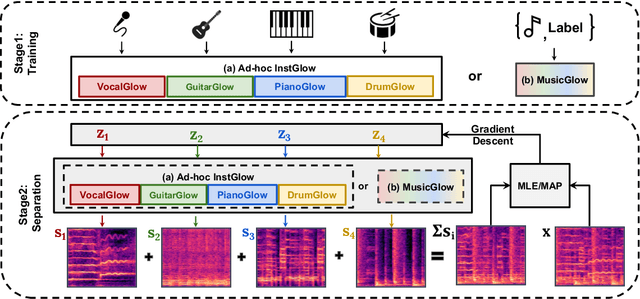
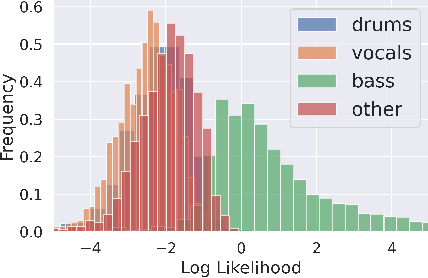

Full supervision models for source separation are trained on mixture-source parallel data and have achieved superior performance in recent years. However, large-scale and naturally mixed parallel training data are difficult to obtain for music, and such models are difficult to adapt to mixtures with new sources. Source-only supervision models, in contrast, only require clean sources for training; They learn source models and then apply these models to separate the mixture.