 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Urban Region Profiling with Adversarial Self-Supervised Learning
Feb 02, 2024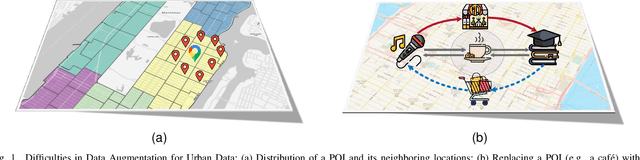
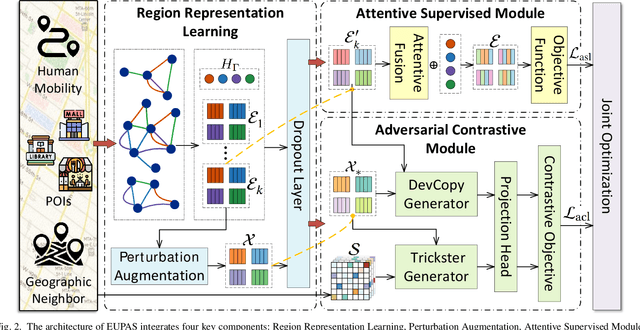
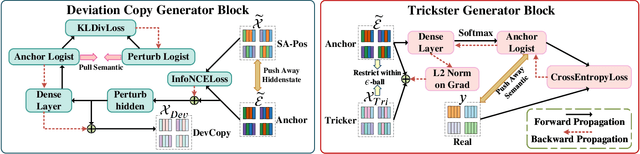
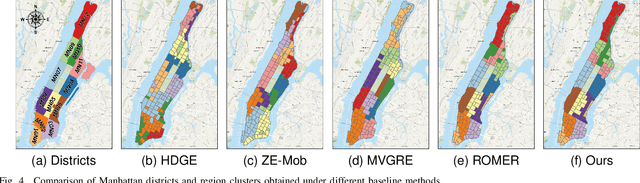
Urban region profiling is pivotal for smart cities, but mining fine-grained semantics from noisy and incomplete urban data remains challenging. In response, we propose a novel self-supervised graph collaborative filtering model for urban region embedding called EUPAS. Specifically, region heterogeneous graphs containing human mobility data, point of interests (POIs) information, and geographic neighborhood details for each region are fed into the model, which generates region embeddings that preserve intra-region and inter-region dependencies through GCNs and multi-head attention. Meanwhile, we introduce spatial perturbation augmentation to generate positive samples that are semantically similar and spatially close to the anchor, preparing for subsequent contrastive learning. Furthermore, adversarial training is employed to construct an effective pretext task by generating strong positive pairs and mining hard negative pairs for the region embeddings. Finally, we jointly optimize supervised and self-supervised learning to encourage the model to capture the high-level semantics of region embeddings while ignoring the noisy and unimportant details. Extensive experiments on real-world datasets demonstrate the superiority of our model over state-of-the-art methods.
Region-Wise Attentive Multi-View Representation Learning for Urban Region Embeddings
Jul 06, 2023



Urban region embedding is an important and yet highly challenging issue due to the complexity and constantly changing nature of urban data. To address the challenges, we propose a Region-Wise Multi-View Representation Learning (ROMER) to capture multi-view dependencies and learn expressive representations of urban regions without the constraints of rigid neighbourhood region conditions. Our model focus on learn urban region representation from multi-source urban data. First, we capture the multi-view correlations from mobility flow patterns, POI semantics and check-in dynamics. Then, we adopt global graph attention networks to learn similarity of any two vertices in graphs. To comprehensively consider and share features of multiple views, a two-stage fusion module is further proposed to learn weights with external attention to fuse multi-view embeddings. Extensive experiments for two downstream tasks on real-world datasets demonstrate that our model outperforms state-of-the-art methods by up to 17\% improvement.