 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurveball Steering: The Right Direction To Steer Isn't Always Linear
Mar 11, 2026Activation steering is a widely used approach for controlling large language model (LLM) behavior by intervening on internal representations. Existing methods largely rely on the Linear Representation Hypothesis, assuming behavioral attributes can be manipulated using global linear directions. In practice, however, such linear interventions often behave inconsistently. We question this assumption by analyzing the intrinsic geometry of LLM activation spaces. Measuring geometric distortion via the ratio of geodesic to Euclidean distances, we observe substantial and concept-dependent distortions, indicating that activation spaces are not well-approximated by a globally linear geometry. Motivated by this, we propose "Curveball steering", a nonlinear steering method based on polynomial kernel PCA that performs interventions in a feature space, better respecting the learned activation geometry. Curveball steering consistently outperforms linear PCA-based steering, particularly in regimes exhibiting strong geometric distortion, suggesting that geometry-aware, nonlinear steering provides a principled alternative to global, linear interventions.
Application of Disentanglement to Map Registration Problem
Aug 26, 2024Geospatial data come from various sources, such as satellites, aircraft, and LiDAR. The variability of the source is not limited to the types of data acquisition techniques, as we have maps from different time periods. To incorporate these data for a coherent analysis, it is essential to first align different "styles" of geospatial data to its matching images that point to the same location on the surface of the Earth. In this paper, we approach the image registration as a two-step process of (1) extracting geospatial contents invariant to visual (and any other non-content-related) information, and (2) matching the data based on such (purely) geospatial contents. We hypothesize that a combination of $\beta$-VAE-like architecture [2] and adversarial training will achieve both the disentanglement of the geographic information and artistic styles and generation of new map tiles by composing the encoded geographic information with any artistic style.
ManiFPT: Defining and Analyzing Fingerprints of Generative Models
Feb 29, 2024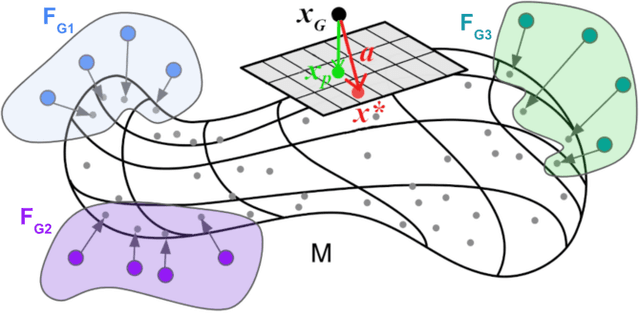
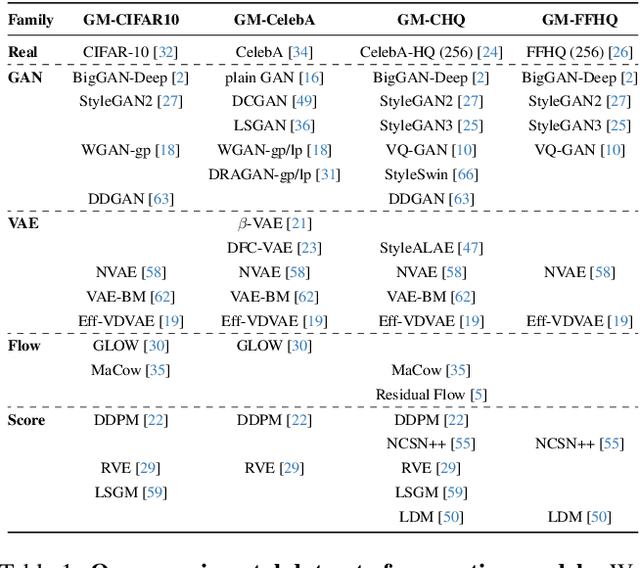
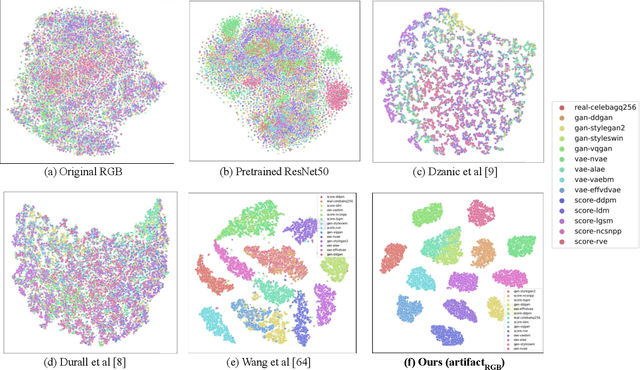
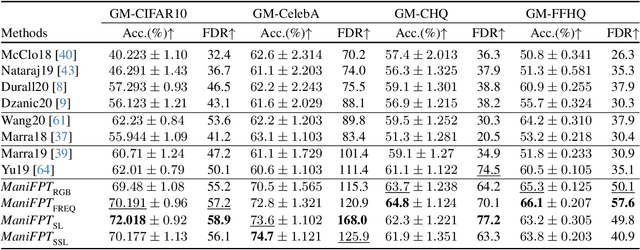
Recent works have shown that generative models leave traces of their underlying generative process on the generated samples, broadly referred to as fingerprints of a generative model, and have studied their utility in detecting synthetic images from real ones. However, the extend to which these fingerprints can distinguish between various types of synthetic image and help identify the underlying generative process remain under-explored. In particular, the very definition of a fingerprint remains unclear, to our knowledge. To that end, in this work, we formalize the definition of artifact and fingerprint in generative models, propose an algorithm for computing them in practice, and finally study its effectiveness in distinguishing a large array of different generative models. We find that using our proposed definition can significantly improve the performance on the task of identifying the underlying generative process from samples (model attribution) compared to existing methods. Additionally, we study the structure of the fingerprints, and observe that it is very predictive of the effect of different design choices on the generative process.
Learning Robust Representations Of Generative Models Using Set-Based Artificial Fingerprints
Jun 04, 2022



With recent progress in deep generative models, the problem of identifying synthetic data and comparing their underlying generative processes has become an imperative task for various reasons, including fighting visual misinformation and source attribution. Existing methods often approximate the distance between the models via their sample distributions. In this paper, we approach the problem of fingerprinting generative models by learning representations that encode the residual artifacts left by the generative models as unique signals that identify the source models. We consider these unique traces (a.k.a. "artificial fingerprints") as representations of generative models, and demonstrate their usefulness in both the discriminative task of source attribution and the unsupervised task of defining a similarity between the underlying models. We first extend the existing studies on fingerprints of GANs to four representative classes of generative models (VAEs, Flows, GANs and score-based models), and demonstrate their existence and attributability. We then improve the stability and attributability of the fingerprints by proposing a new learning method based on set-encoding and contrastive training. Our set-encoder, unlike existing methods that operate on individual images, learns fingerprints from a \textit{set} of images. We demonstrate improvements in the stability and attributability through comparisons to state-of-the-art fingerprint methods and ablation studies. Further, our method employs contrastive training to learn an implicit similarity between models. We discover latent families of generative models using this metric in a standard hierarchical clustering algorithm.