 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Brings the Frisbee: Probing Hidden Hallucination Factors in Large Vision-Language Model via Causality Analysis
Paper and Code
Dec 04, 2024
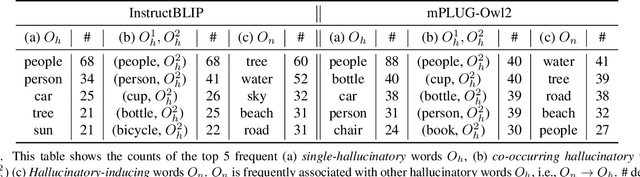

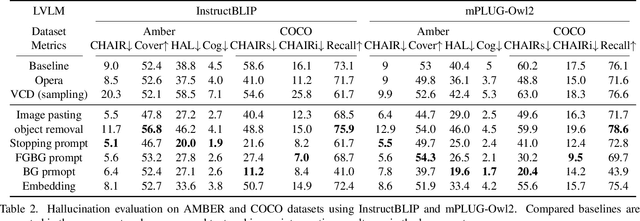
Recent advancements in large vision-language models (LVLM) have significantly enhanced their ability to comprehend visual inputs alongside natural language. However, a major challenge in their real-world application is hallucination, where LVLMs generate non-existent visual elements, eroding user trust. The underlying mechanism driving this multimodal hallucination is poorly understood. Minimal research has illuminated whether contexts such as sky, tree, or grass field involve the LVLM in hallucinating a frisbee. We hypothesize that hidden factors, such as objects, contexts, and semantic foreground-background structures, induce hallucination. This study proposes a novel causal approach: a hallucination probing system to identify these hidden factors. By analyzing the causality between images, text prompts, and network saliency, we systematically explore interventions to block these factors. Our experimental findings show that a straightforward technique based on our analysis can significantly reduce hallucinations. Additionally, our analyses indicate the potential to edit network internals to minimize hallucinated outputs.