 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking the Invisible Visible: Toward High-Quality Terahertz Tomographic Imaging via Physics-Guided Restoration
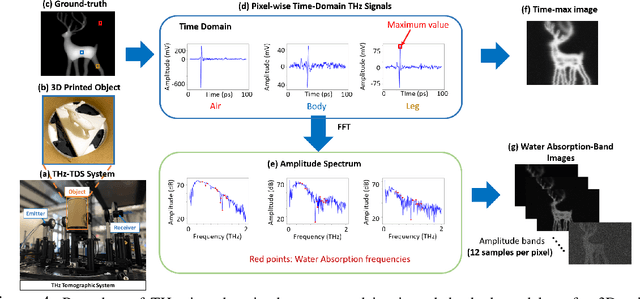
Apr 28, 2023Terahertz (THz) tomographic imaging has recently attracted significant attention thanks to its non-invasive, non-destructive, non-ionizing, material-classification, and ultra-fast nature for object exploration and inspection. However, its strong water absorption nature and low noise tolerance lead to undesired blurs and distortions of reconstructed THz images. The diffraction-limited THz signals highly constrain the performances of existing restoration methods. To address the problem, we propose a novel multi-view Subspace-Attention-guided Restoration Network (SARNet) that fuses multi-view and multi-spectral features of THz images for effective image restoration and 3D tomographic reconstruction. To this end, SARNet uses multi-scale branches to extract intra-view spatio-spectral amplitude and phase features and fuse them via shared subspace projection and self-attention guidance. We then perform inter-view fusion to further improve the restoration of individual views by leveraging the redundancies between neighboring views. Here, we experimentally construct a THz time-domain spectroscopy (THz-TDS) system covering a broad frequency range from 0.1 THz to 4 THz for building up a temporal/spectral/spatial/ material THz database of hidden 3D objects. Complementary to a quantitative evaluation, we demonstrate the effectiveness of our SARNet model on 3D THz tomographic reconstruction applications.
Kinship Representation Learning with Face Componential Relation
Apr 22, 2023Kinship recognition aims to determine whether the subjects in two facial images are kin or non-kin, which is an emerging and challenging problem. However, most previous methods focus on heuristic designs without considering the spatial correlation between face images. In this paper, we aim to learn discriminative kinship representations embedded with the relation information between face components (e.g., eyes, nose, etc.). To achieve this goal, we propose the Face Componential Relation Network, which learns the relationship between face components among images with a cross-attention mechanism, which automatically learns the important facial regions for kinship recognition. Moreover, we propose Face Componential Relation Network (FaCoRNet), which adapts the loss function by the guidance from cross-attention to learn more discriminative feature representations. The proposed FaCoRNet outperforms previous state-of-the-art methods by large margins for the largest public kinship recognition FIW benchmark. The code will be publicly released upon acceptance.
Physics-guided Terahertz Computational Imaging
Apr 30, 2022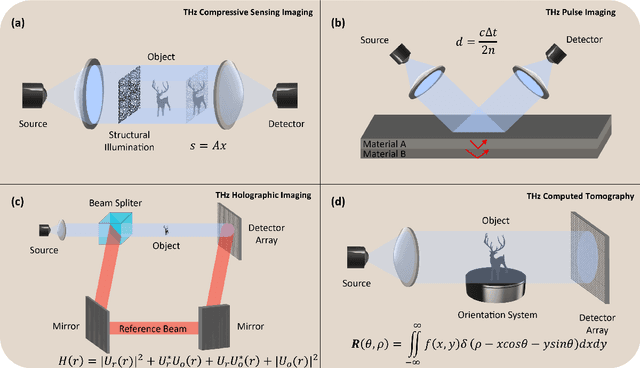
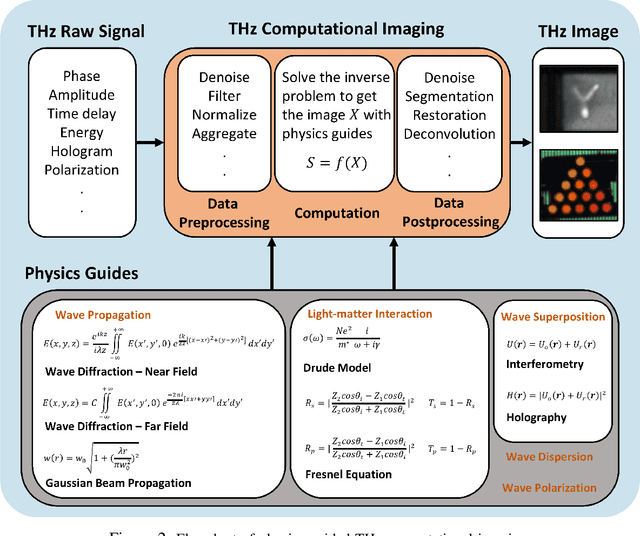
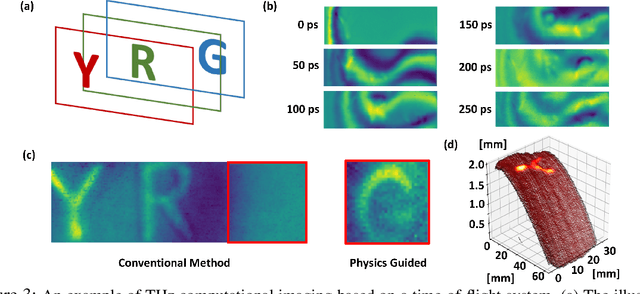
Visualizing information inside objects is an ever-lasting need to bridge the world from physics, chemistry, biology to computation. Among all tomographic techniques, terahertz (THz) computational imaging has demonstrated its unique sensing features to digitalize multi-dimensional object information in a non-destructive, non-ionizing, and non-invasive way. Applying modern signal processing and physics-guided modalities, THz computational imaging systems are now launched in various application fields in industrial inspection, security screening, chemical inspection and non-destructive evaluation. In this article, we overview recent advances in THz computational imaging modalities in the aspects of system configuration, wave propagation and interaction models, physics-guided algorithm for digitalizing interior information of imaged objects. Several image restoration and reconstruction issues based on multi-dimensional THz signals are further discussed, which provides a crosslink between material digitalization, functional property extraction, and multi-dimensional imager utilization from a signal processing perspective.
Keeping Deep Lithography Simulators Updated: Global-Local Shape-Based Novelty Detection and Active Learning
Jan 24, 2022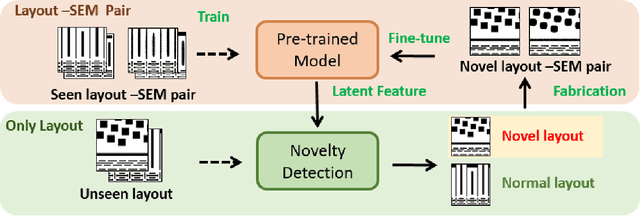
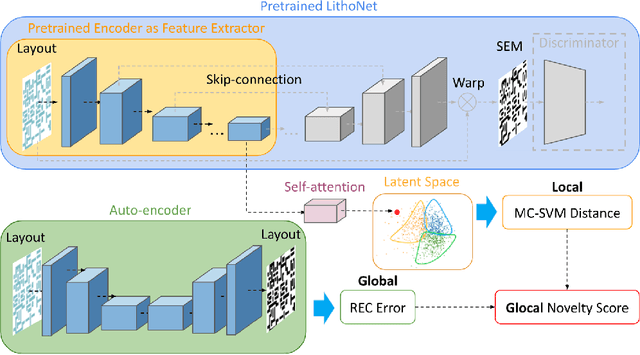
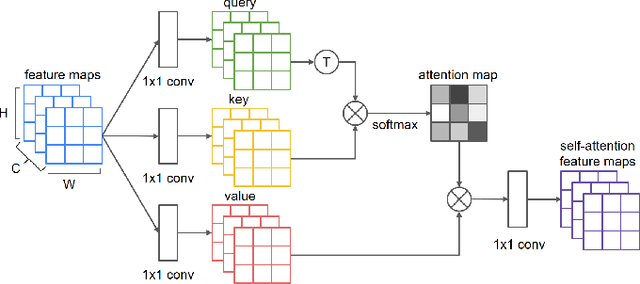

Learning-based pre-simulation (i.e., layout-to-fabrication) models have been proposed to predict the fabrication-induced shape deformation from an IC layout to its fabricated circuit. Such models are usually driven by pairwise learning, involving a training set of layout patterns and their reference shape images after fabrication. However, it is expensive and time-consuming to collect the reference shape images of all layout clips for model training and updating. To address the problem, we propose a deep learning-based layout novelty detection scheme to identify novel (unseen) layout patterns, which cannot be well predicted by a pre-trained pre-simulation model. We devise a global-local novelty scoring mechanism to assess the potential novelty of a layout by exploiting two subnetworks: an autoencoder and a pretrained pre-simulation model. The former characterizes the global structural dissimilarity between a given layout and training samples, whereas the latter extracts a latent code representing the fabrication-induced local deformation. By integrating the global dissimilarity with the local deformation boosted by a self-attention mechanism, our model can accurately detect novelties without the ground-truth circuit shapes of test samples. Based on the detected novelties, we further propose two active-learning strategies to sample a reduced amount of representative layouts most worthy to be fabricated for acquiring their ground-truth circuit shapes. Experimental results demonstrate i) our method's effectiveness in layout novelty detection, and ii) our active-learning strategies' ability in selecting representative novel layouts for keeping a learning-based pre-simulation model updated.
Ensemble Learning with Manifold-Based Data Splitting for Noisy Label Correction
Mar 13, 2021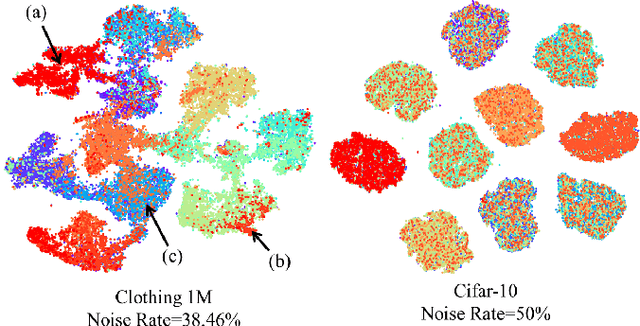
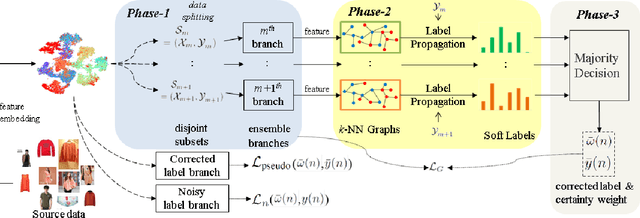
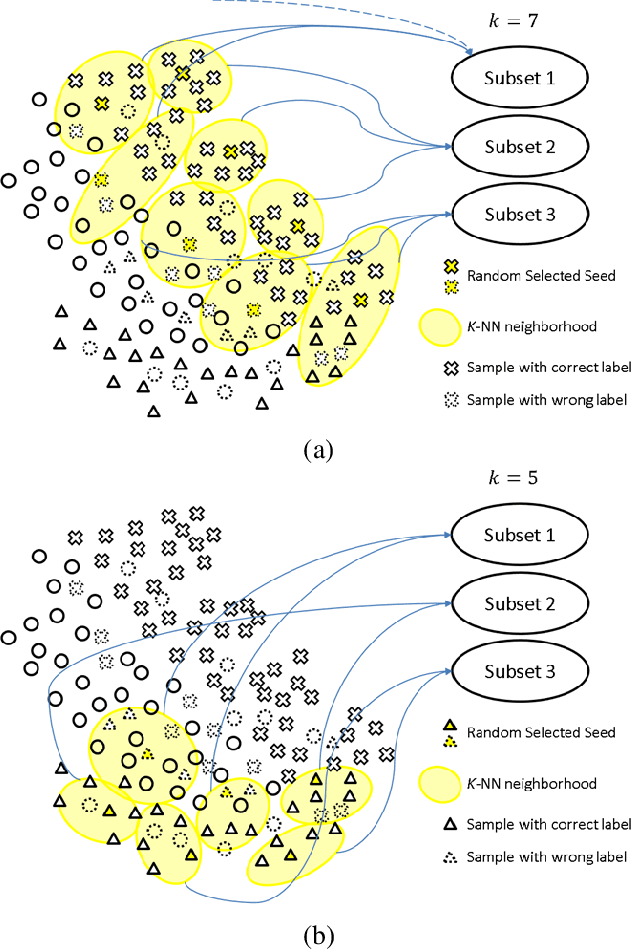
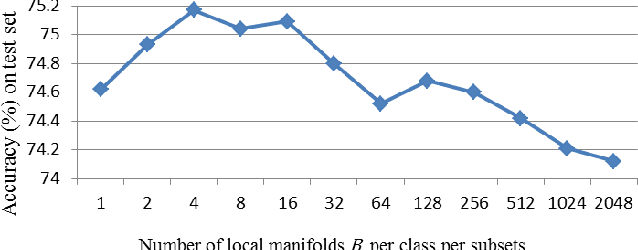
Label noise in training data can significantly degrade a model's generalization performance for supervised learning tasks. Here we focus on the problem that noisy labels are primarily mislabeled samples, which tend to be concentrated near decision boundaries, rather than uniformly distributed, and whose features should be equivocal. To address the problem, we propose an ensemble learning method to correct noisy labels by exploiting the local structures of feature manifolds. Different from typical ensemble strategies that increase the prediction diversity among sub-models via certain loss terms, our method trains sub-models on disjoint subsets, each being a union of the nearest-neighbors of randomly selected seed samples on the data manifold. As a result, each sub-model can learn a coarse representation of the data manifold along with a corresponding graph. Moreover, only a limited number of sub-models will be affected by locally-concentrated noisy labels. The constructed graphs are used to suggest a series of label correction candidates, and accordingly, our method derives label correction results by voting down inconsistent suggestions. Our experiments on real-world noisy label datasets demonstrate the superiority of the proposed method over existing state-of-the-arts.
SiGAN: Siamese Generative Adversarial Network for Identity-Preserving Face Hallucination
Jul 22, 2018
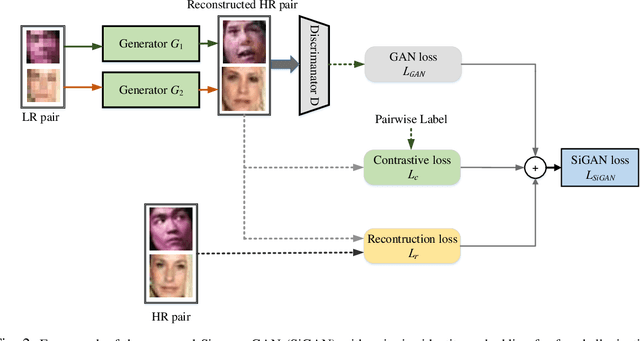
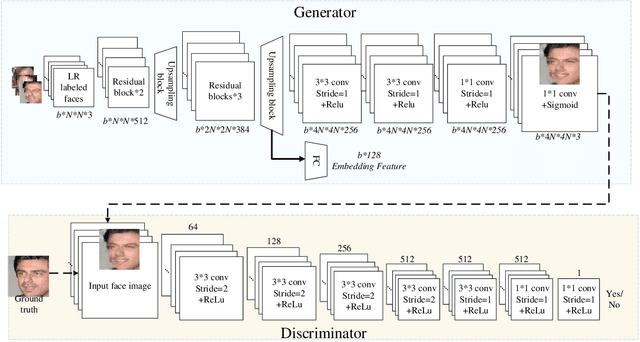
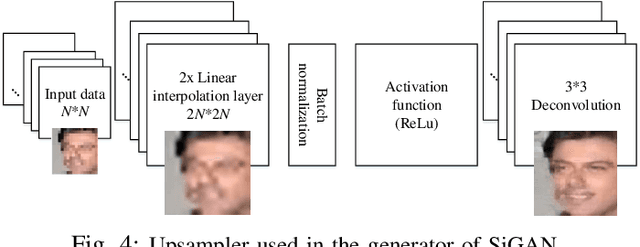
Despite generative adversarial networks (GANs) can hallucinate photo-realistic high-resolution (HR) faces from low-resolution (LR) faces, they cannot guarantee preserving the identities of hallucinated HR faces, making the HR faces poorly recognizable. To address this problem, we propose a Siamese GAN (SiGAN) to reconstruct HR faces that visually resemble their corresponding identities. On top of a Siamese network, the proposed SiGAN consists of a pair of two identical generators and one discriminator. We incorporate reconstruction error and identity label information in the loss function of SiGAN in a pairwise manner. By iteratively optimizing the loss functions of the generator pair and discriminator of SiGAN, we cannot only achieve photo-realistic face reconstruction, but also ensures the reconstructed information is useful for identity recognition. Experimental results demonstrate that SiGAN significantly outperforms existing face hallucination GANs in objective face verification performance, while achieving photo-realistic reconstruction. Moreover, for input LR faces from unknown identities who are not included in training, SiGAN can still do a good job.
Robust Semi-Supervised Graph Classifier Learning with Negative Edge Weights
Jul 20, 2017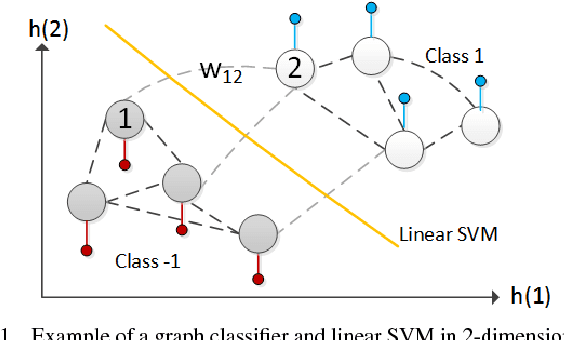
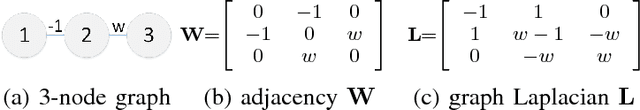
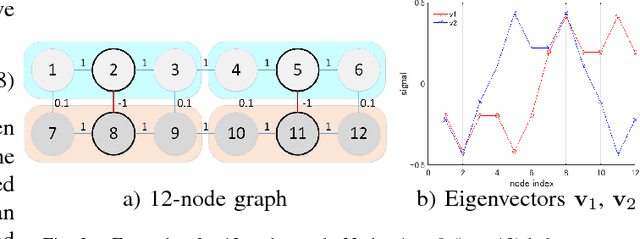
In a semi-supervised learning scenario, (possibly noisy) partially observed labels are used as input to train a classifier, in order to assign labels to unclassified samples. In this paper, we study this classifier learning problem from a graph signal processing (GSP) perspective. Specifically, by viewing a binary classifier as a piecewise constant graph-signal in a high-dimensional feature space, we cast classifier learning as a signal restoration problem via a classical maximum a posteriori (MAP) formulation. Unlike previous graph-signal restoration works, we consider in addition edges with negative weights that signify anti-correlation between samples. One unfortunate consequence is that the graph Laplacian matrix $\mathbf{L}$ can be indefinite, and previously proposed graph-signal smoothness prior $\mathbf{x}^T \mathbf{L} \mathbf{x}$ for candidate signal $\mathbf{x}$ can lead to pathological solutions. In response, we derive an optimal perturbation matrix $\boldsymbol{\Delta}$ - based on a fast lower-bound computation of the minimum eigenvalue of $\mathbf{L}$ via a novel application of the Haynsworth inertia additivity formula---so that $\mathbf{L} + \boldsymbol{\Delta}$ is positive semi-definite, resulting in a stable signal prior. Further, instead of forcing a hard binary decision for each sample, we define the notion of generalized smoothness on graph that promotes ambiguity in the classifier signal. Finally, we propose an algorithm based on iterative reweighted least squares (IRLS) that solves the posed MAP problem efficiently. Extensive simulation results show that our proposed algorithm outperforms both SVM variants and graph-based classifiers using positive-edge graphs noticeably.