 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Learning with Manifold-Based Data Splitting for Noisy Label Correction
Paper and Code
Mar 13, 2021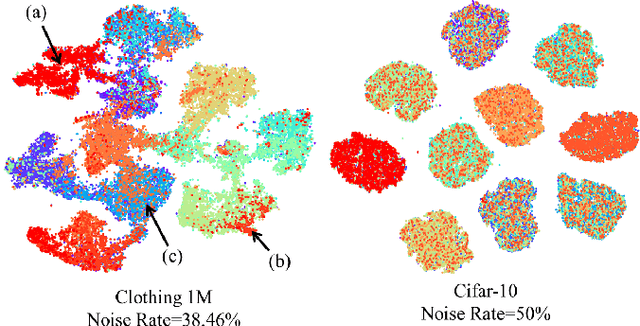
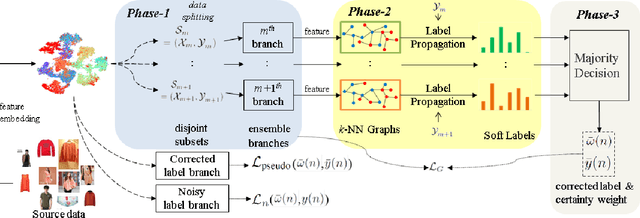
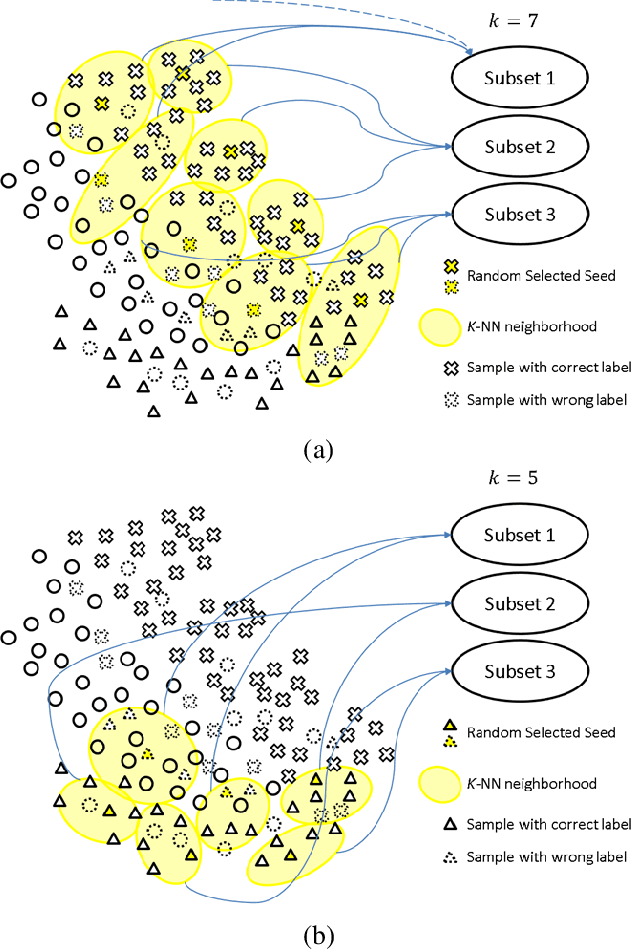
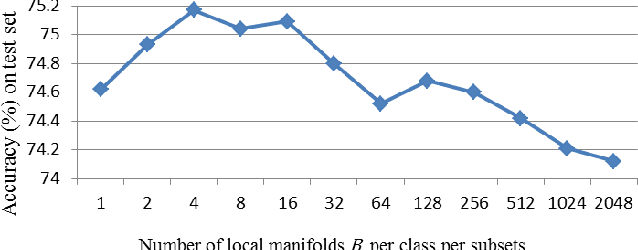
Label noise in training data can significantly degrade a model's generalization performance for supervised learning tasks. Here we focus on the problem that noisy labels are primarily mislabeled samples, which tend to be concentrated near decision boundaries, rather than uniformly distributed, and whose features should be equivocal. To address the problem, we propose an ensemble learning method to correct noisy labels by exploiting the local structures of feature manifolds. Different from typical ensemble strategies that increase the prediction diversity among sub-models via certain loss terms, our method trains sub-models on disjoint subsets, each being a union of the nearest-neighbors of randomly selected seed samples on the data manifold. As a result, each sub-model can learn a coarse representation of the data manifold along with a corresponding graph. Moreover, only a limited number of sub-models will be affected by locally-concentrated noisy labels. The constructed graphs are used to suggest a series of label correction candidates, and accordingly, our method derives label correction results by voting down inconsistent suggestions. Our experiments on real-world noisy label datasets demonstrate the superiority of the proposed method over existing state-of-the-arts.