 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeTformer is What You Need for Vision and Language
Paper and Code
Jan 07, 2024

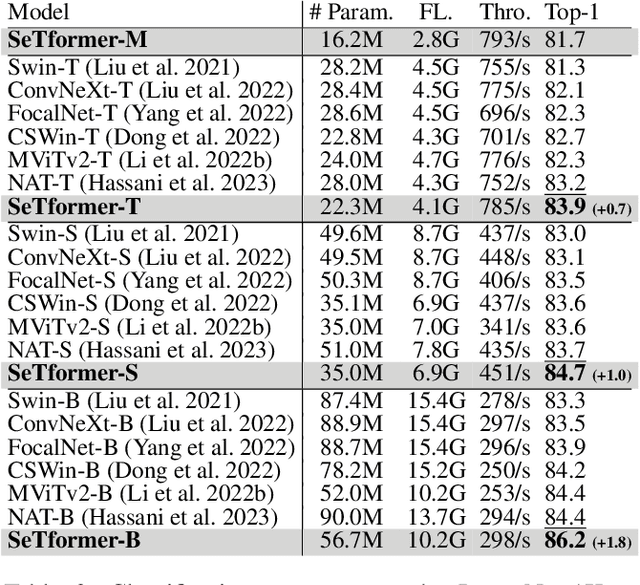
The dot product self-attention (DPSA) is a fundamental component of transformers. However, scaling them to long sequences, like documents or high-resolution images, becomes prohibitively expensive due to quadratic time and memory complexities arising from the softmax operation. Kernel methods are employed to simplify computations by approximating softmax but often lead to performance drops compared to softmax attention. We propose SeTformer, a novel transformer, where DPSA is purely replaced by Self-optimal Transport (SeT) for achieving better performance and computational efficiency. SeT is based on two essential softmax properties: maintaining a non-negative attention matrix and using a nonlinear reweighting mechanism to emphasize important tokens in input sequences. By introducing a kernel cost function for optimal transport, SeTformer effectively satisfies these properties. In particular, with small and basesized models, SeTformer achieves impressive top-1 accuracies of 84.7% and 86.2% on ImageNet-1K. In object detection, SeTformer-base outperforms the FocalNet counterpart by +2.2 mAP, using 38% fewer parameters and 29% fewer FLOPs. In semantic segmentation, our base-size model surpasses NAT by +3.5 mIoU with 33% fewer parameters. SeTformer also achieves state-of-the-art results in language modeling on the GLUE benchmark. These findings highlight SeTformer's applicability in vision and language tasks.