 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Weighted Trans Network for Image Completion
Paper and Code
Oct 25, 2023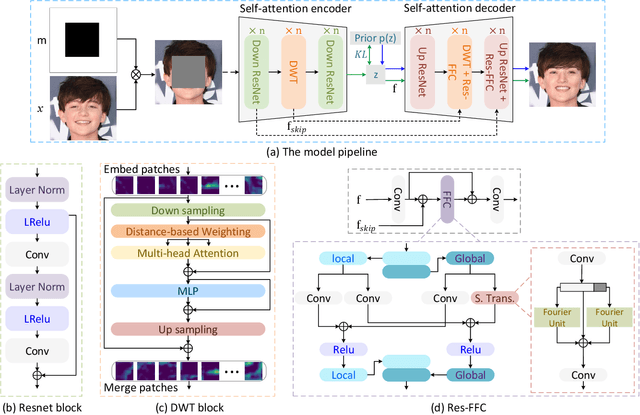
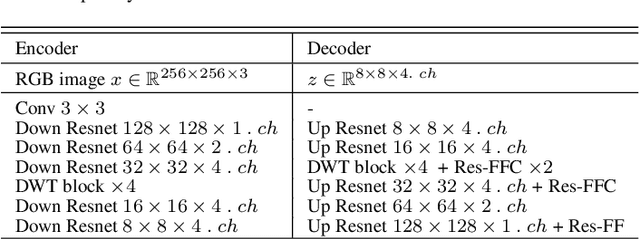

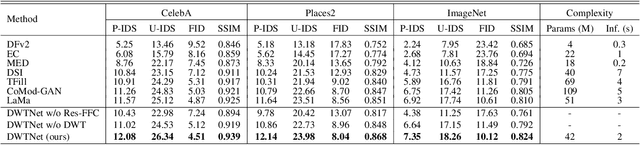
The challenge of image generation has been effectively modeled as a problem of structure priors or transformation. However, existing models have unsatisfactory performance in understanding the global input image structures because of particular inherent features (for example, local inductive prior). Recent studies have shown that self-attention is an efficient modeling technique for image completion problems. In this paper, we propose a new architecture that relies on Distance-based Weighted Transformer (DWT) to better understand the relationships between an image's components. In our model, we leverage the strengths of both Convolutional Neural Networks (CNNs) and DWT blocks to enhance the image completion process. Specifically, CNNs are used to augment the local texture information of coarse priors and DWT blocks are used to recover certain coarse textures and coherent visual structures. Unlike current approaches that generally use CNNs to create feature maps, we use the DWT to encode global dependencies and compute distance-based weighted feature maps, which substantially minimizes the problem of visual ambiguities. Meanwhile, to better produce repeated textures, we introduce Residual Fast Fourier Convolution (Res-FFC) blocks to combine the encoder's skip features with the coarse features provided by our generator. Furthermore, a simple yet effective technique is proposed to normalize the non-zero values of convolutions, and fine-tune the network layers for regularization of the gradient norms to provide an efficient training stabiliser. Extensive quantitative and qualitative experiments on three challenging datasets demonstrate the superiority of our proposed model compared to existing approaches.