 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal overlap reduction procedure for dynamic ensemble selection
Jun 16, 2022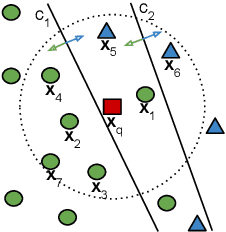
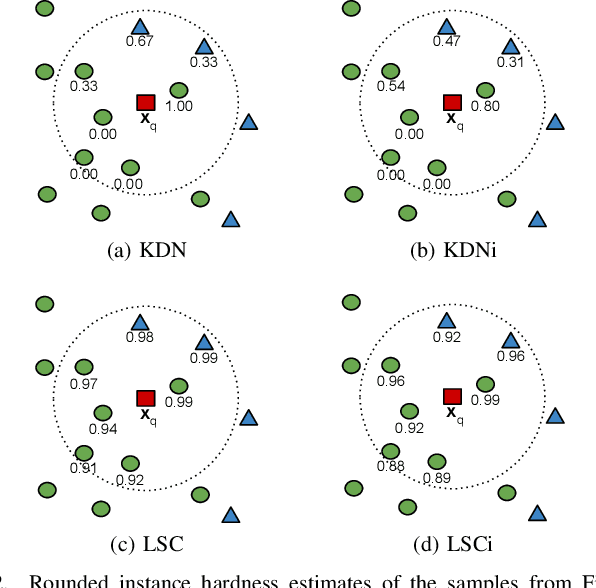
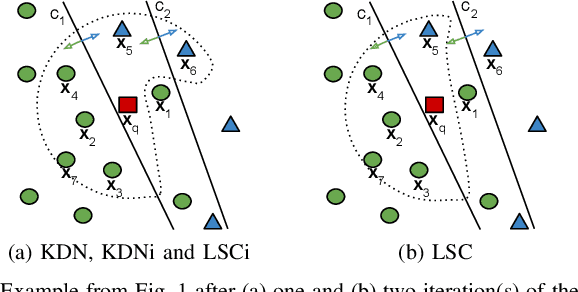
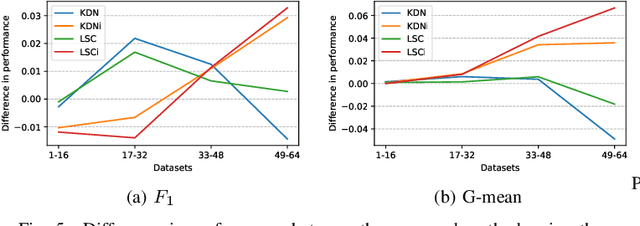
Class imbalance is a characteristic known for making learning more challenging for classification models as they may end up biased towards the majority class. A promising approach among the ensemble-based methods in the context of imbalance learning is Dynamic Selection (DS). DS techniques single out a subset of the classifiers in the ensemble to label each given unknown sample according to their estimated competence in the area surrounding the query. Because only a small region is taken into account in the selection scheme, the global class disproportion may have less impact over the system's performance. However, the presence of local class overlap may severely hinder the DS techniques' performance over imbalanced distributions as it not only exacerbates the effects of the under-representation but also introduces ambiguous and possibly unreliable samples to the competence estimation process. Thus, in this work, we propose a DS technique which attempts to minimize the effects of the local class overlap during the classifier selection procedure. The proposed method iteratively removes from the target region the instance perceived as the hardest to classify until a classifier is deemed competent to label the query sample. The known samples are characterized using instance hardness measures that quantify the local class overlap. Experimental results show that the proposed technique can significantly outperform the baseline as well as several other DS techniques, suggesting its suitability for dealing with class under-representation and overlap. Furthermore, the proposed technique still yielded competitive results when using an under-sampled, less overlapped version of the labelled sets, specially over the problems with a high proportion of minority class samples in overlap areas. Code available at https://github.com/marianaasouza/lords.
Multi-label learning for dynamic model type recommendation
Apr 01, 2020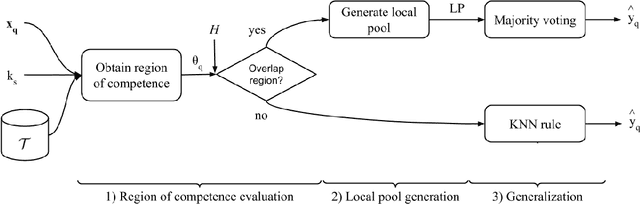
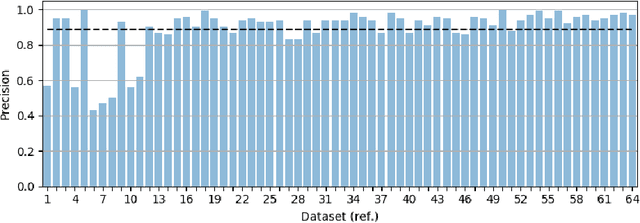
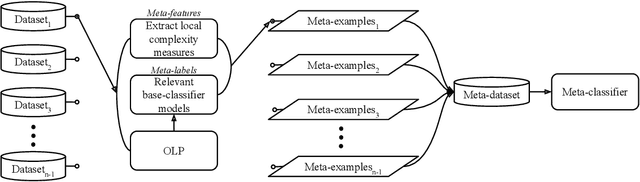
Dynamic selection techniques aim at selecting the local experts around each test sample in particular for performing its classification. While generating the classifier on a local scope may make it easier for singling out the locally competent ones, as in the online local pool (OLP) technique, using the same base-classifier model in uneven distributions may restrict the local level of competence, since each region may have a data distribution that favors one model over the others. Thus, we propose in this work a problem-independent dynamic base-classifier model recommendation for the OLP technique, which uses information regarding the behavior of a portfolio of models over the samples of different problems to recommend one (or several) of them on a per-instance manner. Our proposed framework builds a multi-label meta-classifier responsible for recommending a set of relevant model types based on the local data complexity of the region surrounding each test sample. The OLP technique then produces a local pool with the model that yields the highest probability score of the meta-classifier. Experimental results show that different data distributions favored different model types on a local scope. Moreover, based on the performance of an ideal model type selector, it was observed that there is a clear advantage in choosing a relevant model type for each test instance. Overall, the proposed model type recommender system yielded a statistically similar performance to the original OLP with fixed base-classifier model. Given the novelty of the approach and the gap in performance between the proposed framework and the ideal selector, we regard this as a promising research direction. Code available at github.com/marianaasouza/dynamic-model-recommender.
ICPRAI 2018 SI: On dynamic ensemble selection and data preprocessing for multi-class imbalance learning
Nov 29, 2018



Class-imbalance refers to classification problems in which many more instances are available for certain classes than for others. Such imbalanced datasets require special attention because traditional classifiers generally favor the majority class which has a large number of instances. Ensemble of classifiers have been reported to yield promising results. However, the majority of ensemble methods applied to imbalanced learning are static ones. Moreover, they only deal with binary imbalanced problems. Hence, this paper presents an empirical analysis of dynamic selection techniques and data preprocessing methods for dealing with multi-class imbalanced problems. We considered five variations of preprocessing methods and fourteen dynamic selection schemes. Our experiments conducted on 26 multi-class imbalanced problems show that the dynamic ensemble improves the AUC and the G-mean as compared to the static ensemble. Moreover, data preprocessing plays an important role in such cases.
Online local pool generation for dynamic classifier selection: an extended version
Sep 05, 2018



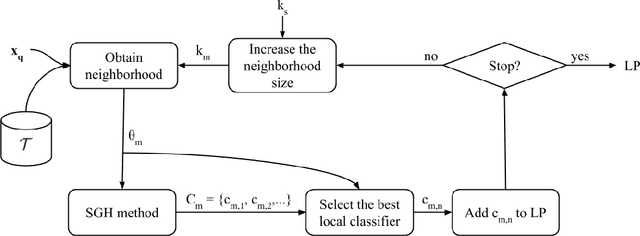
Dynamic Classifier Selection (DCS) techniques have difficulty in selecting the most competent classifier in a pool, even when its presence is assured. Since the DCS techniques rely only on local data to estimate a classifier's competence, the manner in which the pool is generated could affect the choice of the best classifier for a given sample. That is, the global perspective in which pools are generated may not help the DCS techniques in selecting a competent classifier for samples that are likely to be mislabelled. Thus, we propose in this work an online pool generation method that produces a locally accurate pool for test samples in difficult regions of the feature space. The difficulty of a given area is determined by the classification difficulty of the samples in it. That way, by using classifiers that were generated in a local scope, it could be easier for the DCS techniques to select the best one for the difficult samples. For the query samples in easy regions, a simple nearest neighbors rule is used. In the extended version of this work, a deep analysis on the correlation between instance hardness and the performance of DCS techniques is presented. An instance hardness measure that conveys the degree of local class overlap is then used to decide when the local pool is used in the proposed scheme. The proposed method yielded significantly greater recognition rates in comparison to a Bagging-generated pool and two other global pool generation schemes for all DCS techniques evaluated. The proposed scheme's performance was also significantly superior to three state-of-the-art classification models and statistically equivalent to five of them. Moreover, an extended analysis on the computational complexity of the proposed method and of several DS techniques is presented in this version. We also provide the implementation of the proposed technique using the DESLib library on GitHub.