 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Commercial ASR Systems on Code-Switching Speech: Arabic, Persian, and German
May 21, 2026Code-switching -- the natural alternation between two languages within a single utterance -- represents one of the most challenging and under-studied conditions for automatic speech recognition (ASR). Existing commercial ASR benchmarks predominantly evaluate clean, monolingual audio and report a single Word Error Rate (WER) figure that tells practitioners little about real-world multilingual performance. We present a benchmark evaluating five commercial ASR providers across four language pairs: Egyptian Arabic--English, Saudi Arabic (Najdi/Hijazi)--English, Persian (Farsi)--English, and German--English. Each dataset comprises 300 samples selected by a two-stage pipeline: a heuristic filter scoring transcripts on five structural code-switching signals, followed by a GPT-4o and Gemini 1.5 Pro ensemble scoring candidates across six linguistic dimensions. This pipeline reduces LLM scoring costs by approximately 91% relative to exhaustive scoring. We evaluate the systems on both WER and BERTScore, arguing that BERTScore is a more reliable metric for Arabic and Persian pairs where transliteration variance causes WER to penalise semantically correct transcriptions. ElevenLabs Scribe v2 achieves the lowest WER across all four language pairs (13.2% overall; 13.1% on Egyptian Arabic) and leads on BERTScore (0.936 overall). We further demonstrate that difficulty-stratified analysis reveals performance gaps masked by aggregate averages, and that BERT embedding projections confirm semantic proximity between reference and hypothesis despite surface-level script differences. The benchmarking dataset is publicly available at https://huggingface.co/datasets/Perle-ai/ASR_Code_Switch.
Peer-Ranked Precision: Creating a Foundational Dataset for Fine-Tuning Vision Models from DataSeeds' Annotated Imagery
Jun 06, 2025The development of modern Artificial Intelligence (AI) models, particularly diffusion-based models employed in computer vision and image generation tasks, is undergoing a paradigmatic shift in development methodologies. Traditionally dominated by a "Model Centric" approach, in which performance gains were primarily pursued through increasingly complex model architectures and hyperparameter optimization, the field is now recognizing a more nuanced "Data-Centric" approach. This emergent framework foregrounds the quality, structure, and relevance of training data as the principal driver of model performance. To operationalize this paradigm shift, we introduce the DataSeeds.AI sample dataset (the "DSD"), initially comprised of approximately 10,610 high-quality human peer-ranked photography images accompanied by extensive multi-tier annotations. The DSD is a foundational computer vision dataset designed to usher in a new standard for commercial image datasets. Representing a small fraction of DataSeed.AI's 100 million-plus image catalog, the DSD provides a scalable foundation necessary for robust commercial and multimodal AI development. Through this in-depth exploratory analysis, we document the quantitative improvements generated by the DSD on specific models against known benchmarks and make the code and the trained models used in our evaluation publicly available.
Self-supervised learning for infant cry analysis
May 02, 2023



In this paper, we explore self-supervised learning (SSL) for analyzing a first-of-its-kind database of cry recordings containing clinical indications of more than a thousand newborns. Specifically, we target cry-based detection of neurological injury as well as identification of cry triggers such as pain, hunger, and discomfort. Annotating a large database in the medical setting is expensive and time-consuming, typically requiring the collaboration of several experts over years. Leveraging large amounts of unlabeled audio data to learn useful representations can lower the cost of building robust models and, ultimately, clinical solutions. In this work, we experiment with self-supervised pre-training of a convolutional neural network on large audio datasets. We show that pre-training with SSL contrastive loss (SimCLR) performs significantly better than supervised pre-training for both neuro injury and cry triggers. In addition, we demonstrate further performance gains through SSL-based domain adaptation using unlabeled infant cries. We also show that using such SSL-based pre-training for adaptation to cry sounds decreases the need for labeled data of the overall system.
Knowledge Distillation for Multi-Target Domain Adaptation in Real-Time Person Re-Identification
May 12, 2022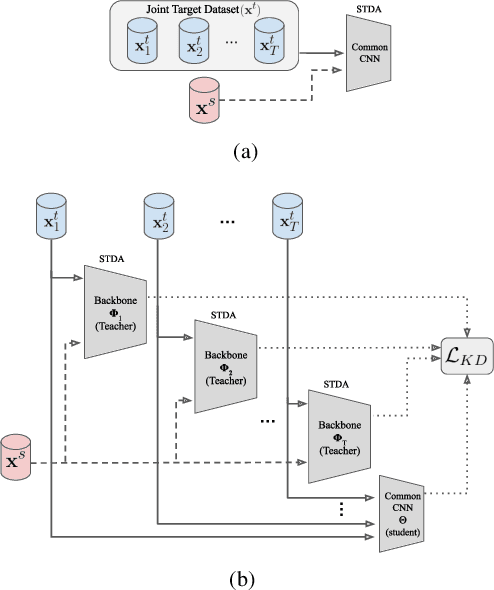
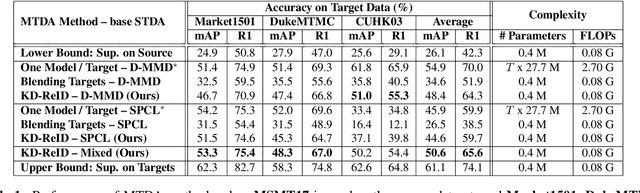
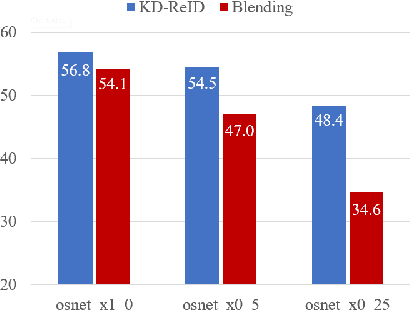
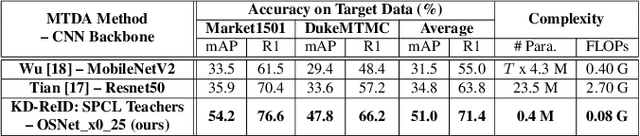
Despite the recent success of deep learning architectures, person re-identification (ReID) remains a challenging problem in real-word applications. Several unsupervised single-target domain adaptation (STDA) methods have recently been proposed to limit the decline in ReID accuracy caused by the domain shift that typically occurs between source and target video data. Given the multimodal nature of person ReID data (due to variations across camera viewpoints and capture conditions), training a common CNN backbone to address domain shifts across multiple target domains, can provide an efficient solution for real-time ReID applications. Although multi-target domain adaptation (MTDA) has not been widely addressed in the ReID literature, a straightforward approach consists in blending different target datasets, and performing STDA on the mixture to train a common CNN. However, this approach may lead to poor generalization, especially when blending a growing number of distinct target domains to train a smaller CNN. To alleviate this problem, we introduce a new MTDA method based on knowledge distillation (KD-ReID) that is suitable for real-time person ReID applications. Our method adapts a common lightweight student backbone CNN over the target domains by alternatively distilling from multiple specialized teacher CNNs, each one adapted on data from a specific target domain. Extensive experiments conducted on several challenging person ReID datasets indicate that our approach outperforms state-of-art methods for MTDA, including blending methods, particularly when training a compact CNN backbone like OSNet. Results suggest that our flexible MTDA approach can be employed to design cost-effective ReID systems for real-time video surveillance applications.
Cross-Representation Transferability of Adversarial Perturbations: From Spectrograms to Audio Waveforms
Oct 22, 2019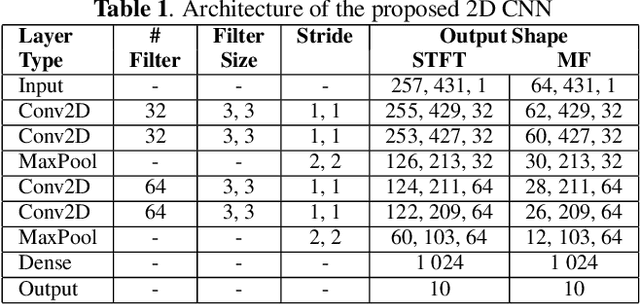
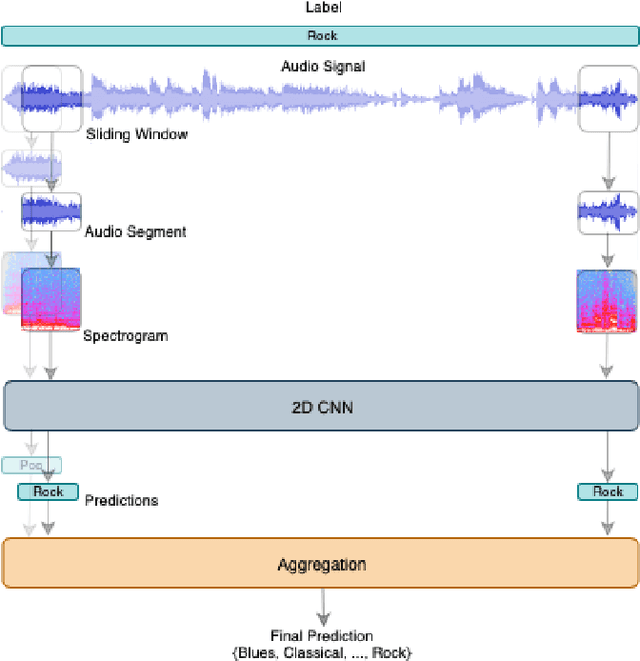
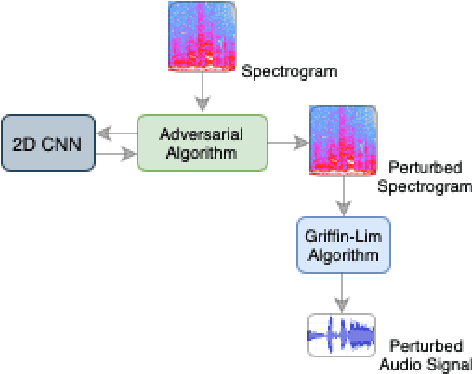

This paper shows the susceptibility of spectrogram-based audio classifiers to adversarial attacks and the transferability of such attacks to audio waveforms. Some commonly adversarial attacks to images have been applied to Mel-frequency and short-time Fourier transform spectrograms and such perturbed spectrograms are able to fool a 2D convolutional neural network (CNN) for music genre classification with a high fooling rate and high confidence. Such attacks produce perturbed spectrograms that are visually imperceptible by humans. Experimental results on a dataset of western music have shown that the 2D CNN achieves up to 81.87% of mean accuracy on legitimate examples and such a performance drops to 12.09% on adversarial examples. Furthermore, the audio signals reconstructed from the adversarial spectrograms produce audio waveforms that perceptually resemble the legitimate audio.
Universal Adversarial Audio Perturbations
Aug 12, 2019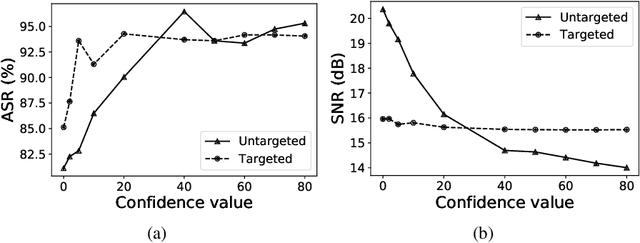
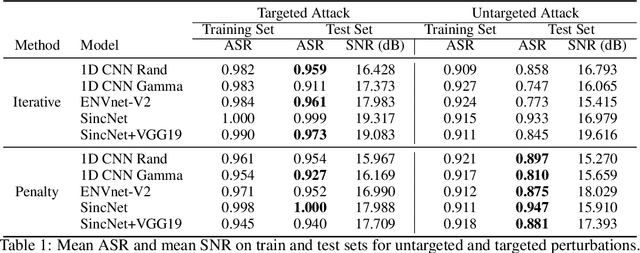
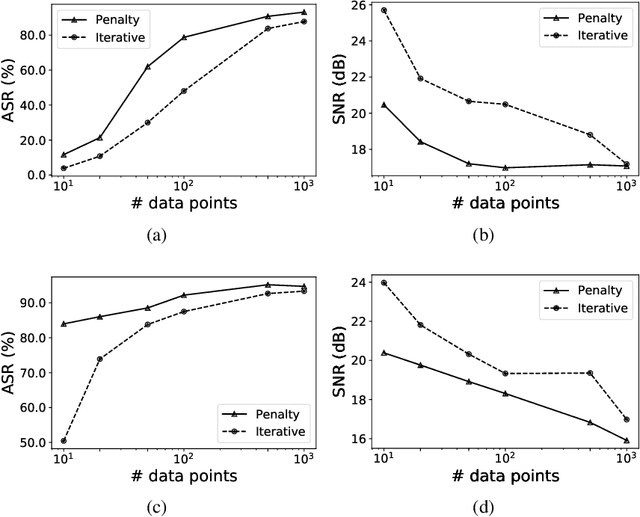
We demonstrate the existence of universal adversarial perturbations, which can fool a family of audio processing architectures, for both targeted and untargeted attacks. To the best of our knowledge, this is the first study on generating universal adversarial perturbations for audio processing systems. We propose two methods for finding such perturbations. The first method is based on an iterative, greedy approach that is well-known in computer vision: it aggregates small perturbations to the input so as to push it to the decision boundary. The second method, which is the main technical contribution of this work, is a novel penalty formulation, which finds targeted and untargeted universal adversarial perturbations. Differently from the greedy approach, the penalty method minimizes an appropriate objective function on a batch of samples. Therefore, it produces more successful attacks when the number of training samples is limited. Moreover, we provide a proof that the proposed penalty method theoretically converges to a solution that corresponds to universal adversarial perturbations. We report comprehensive experiments, showing attack success rates higher than 91.1% and 74.7% for targeted and untargeted attacks, respectively.
End-to-End Environmental Sound Classification using a 1D Convolutional Neural Network
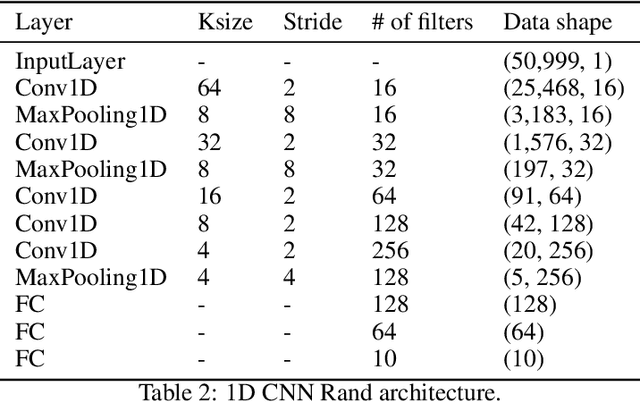
Apr 18, 2019
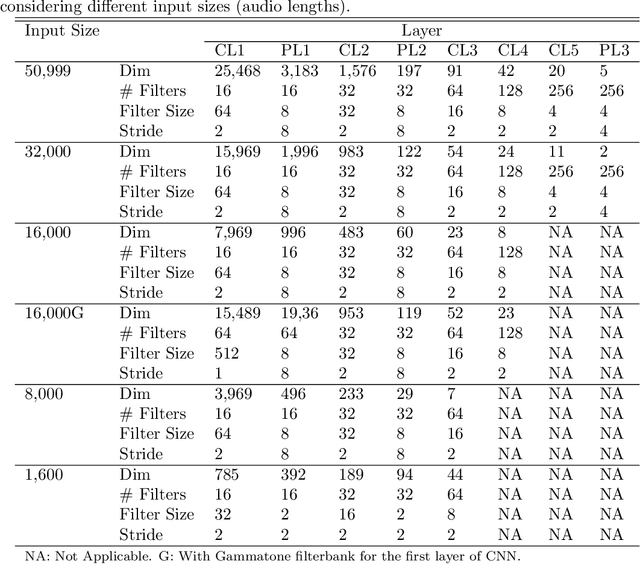
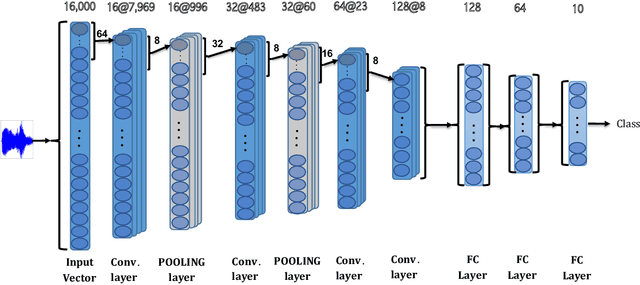
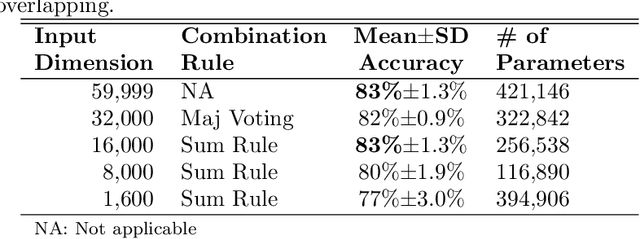
In this paper, we present an end-to-end approach for environmental sound classification based on a 1D Convolution Neural Network (CNN) that learns a representation directly from the audio signal. Several convolutional layers are used to capture the signal's fine time structure and learn diverse filters that are relevant to the classification task. The proposed approach can deal with audio signals of any length as it splits the signal into overlapped frames using a sliding window. Different architectures considering several input sizes are evaluated, including the initialization of the first convolutional layer with a Gammatone filterbank that models the human auditory filter response in the cochlea. The performance of the proposed end-to-end approach in classifying environmental sounds was assessed on the UrbanSound8k dataset and the experimental results have shown that it achieves 89% of mean accuracy. Therefore, the propose approach outperforms most of the state-of-the-art approaches that use handcrafted features or 2D representations as input. Furthermore, the proposed approach has a small number of parameters compared to other architectures found in the literature, which reduces the amount of data required for training.