 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation in Person re-ID via k-Reciprocal Clustering and Large-Scale Heterogeneous Environment Synthesis
Jan 14, 2020
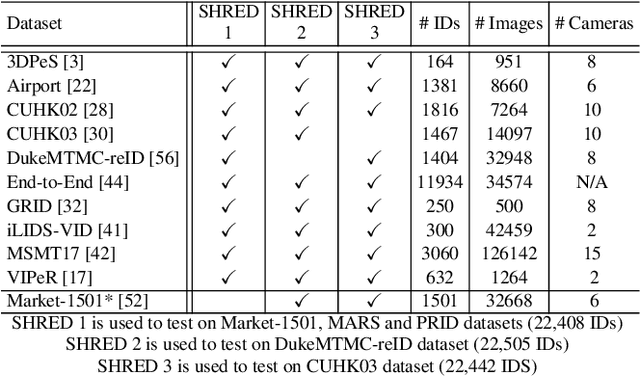
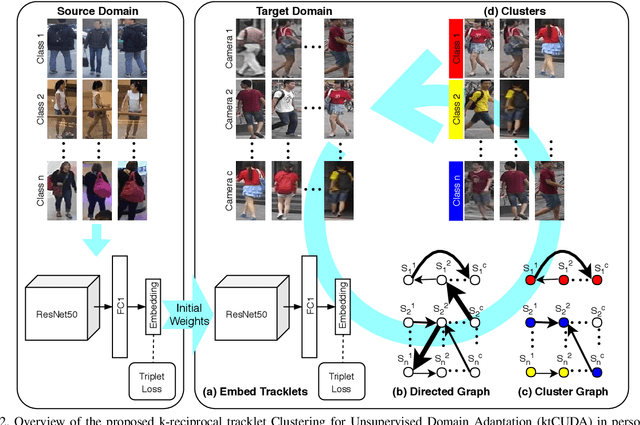
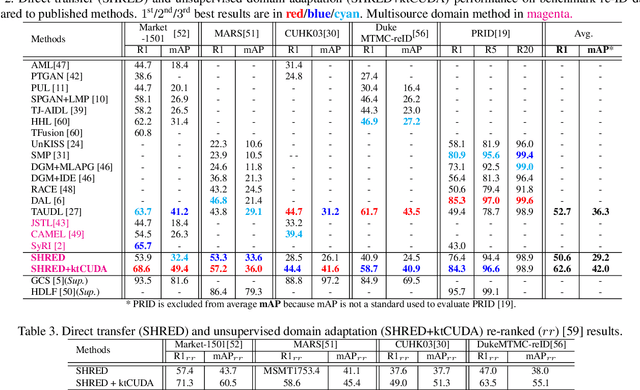
An ongoing major challenge in computer vision is the task of person re-identification, where the goal is to match individuals across different, non-overlapping camera views. While recent success has been achieved via supervised learning using deep neural networks, such methods have limited widespread adoption due to the need for large-scale, customized data annotation. As such, there has been a recent focus on unsupervised learning approaches to mitigate the data annotation issue; however, current approaches in literature have limited performance compared to supervised learning approaches as well as limited applicability for adoption in new environments. In this paper, we address the aforementioned challenges faced in person re-identification for real-world, practical scenarios by introducing a novel, unsupervised domain adaptation approach for person re-identification. This is accomplished through the introduction of: i) k-reciprocal tracklet Clustering for Unsupervised Domain Adaptation (ktCUDA) (for pseudo-label generation on target domain), and ii) Synthesized Heterogeneous RE-id Domain (SHRED) composed of large-scale heterogeneous independent source environments (for improving robustness and adaptability to a wide diversity of target environments). Experimental results across four different image and video benchmark datasets show that the proposed ktCUDA and SHRED approach achieves an average improvement of +5.7 mAP in re-identification performance when compared to existing state-of-the-art methods, as well as demonstrate better adaptability to different types of environments.
Fairest of Them All: Establishing a Strong Baseline for Cross-Domain Person ReID
Jul 28, 2019
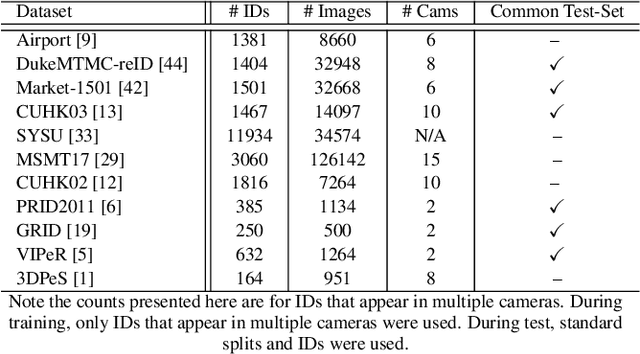

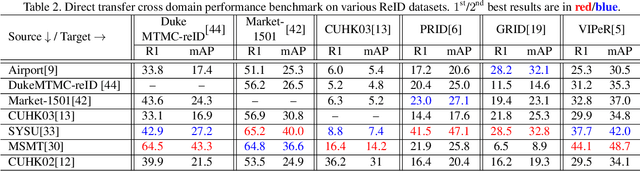
Person re-identification (ReID) remains a very difficult challenge in computer vision, and critical for large-scale video surveillance scenarios where an individual could appear in different camera views at different times. There has been recent interest in tackling this challenge using cross-domain approaches, which leverages data from source domains that are different than the target domain. Such approaches are more practical for real-world widespread deployment given that they don't require on-site training (as with unsupervised or domain transfer approaches) or on-site manual annotation and training (as with supervised approaches). In this study, we take a systematic approach to establishing a large baseline source domain and target domain for cross-domain person ReID. We accomplish this by conducting a comprehensive analysis to study the similarities between source domains proposed in literature, and studying the effects of incrementally increasing the size of the source domain. This allows us to establish a balanced source domain and target domain split that promotes variety in both source and target domains. Furthermore, using lessons learned from the state-of-the-art supervised person re-identification methods, we establish a strong baseline method for cross-domain person ReID. Experiments show that a source domain composed of two of the largest person ReID domains (SYSU and MSMT) performs well across six commonly-used target domains. Furthermore, we show that, surprisingly, two of the recent commonly-used domains (PRID and GRID) have too few query images to provide meaningful insights. As such, based on our findings, we propose the following balanced baseline for cross-domain person ReID consisting of: i) a fixed multi-source domain consisting of SYSU, MSMT, Airport and 3DPeS, and ii) a multi-target domain consisting of Market-1501, DukeMTMC-reID, CUHK03, PRID, GRID and VIPeR.
An Evaluation of Deep CNN Baselines for Scene-Independent Person Re-Identification
May 16, 2018
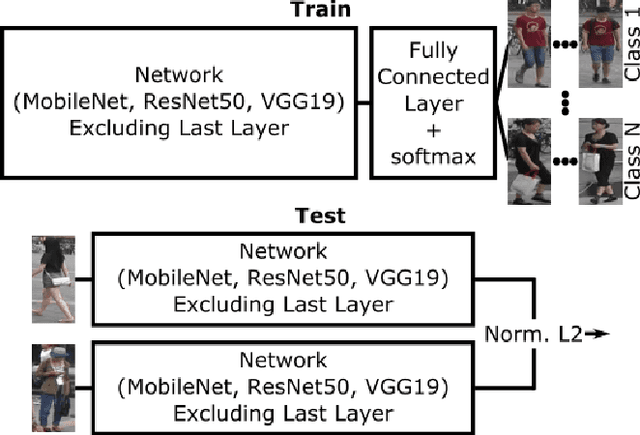

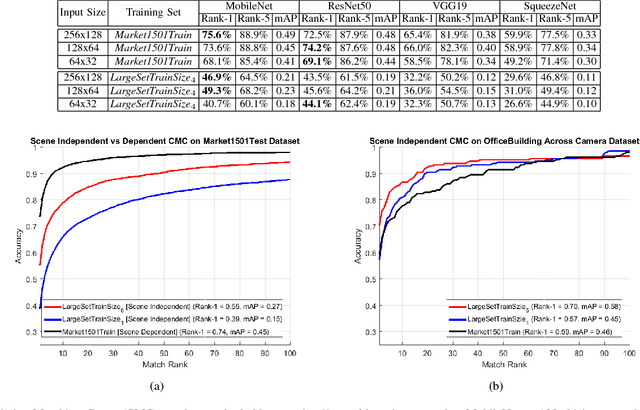
In recent years, a variety of proposed methods based on deep convolutional neural networks (CNNs) have improved the state of the art for large-scale person re-identification (ReID). While a large number of optimizations and network improvements have been proposed, there has been relatively little evaluation of the influence of training data and baseline network architecture. In particular, it is usually assumed either that networks are trained on labeled data from the deployment location (scene-dependent), or else adapted with unlabeled data, both of which complicate system deployment. In this paper, we investigate the feasibility of achieving scene-independent person ReID by forming a large composite dataset for training. We present an in-depth comparison of several CNN baseline architectures for both scene-dependent and scene-independent ReID, across a range of training dataset sizes. We show that scene-independent ReID can produce leading-edge results, competitive with unsupervised domain adaption techniques. Finally, we introduce a new dataset for comparing within-camera and across-camera person ReID.