 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayer Identification in Hockey Broadcast Videos
Sep 14, 2020



We present a deep recurrent convolutional neural network (CNN) approach to solve the problem of hockey player identification in NHL broadcast videos. Player identification is a difficult computer vision problem mainly because of the players' similar appearance, occlusion, and blurry facial and physical features. However, we can observe players' jersey numbers over time by processing variable length image sequences of players (aka 'tracklets'). We propose an end-to-end trainable ResNet+LSTM network, with a residual network (ResNet) base and a long short-term memory (LSTM) layer, to discover spatio-temporal features of jersey numbers over time and learn long-term dependencies. For this work, we created a new hockey player tracklet dataset that contains sequences of hockey player bounding boxes. Additionally, we employ a secondary 1-dimensional convolutional neural network classifier as a late score-level fusion method to classify the output of the ResNet+LSTM network. This achieves an overall player identification accuracy score over 87% on the test split of our new dataset.
Video Anomaly Detection and Localization via Gaussian Mixture Fully Convolutional Variational Autoencoder
May 29, 2018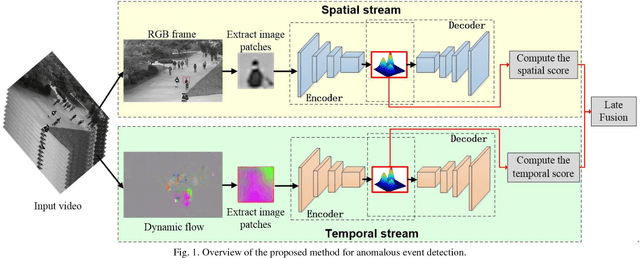

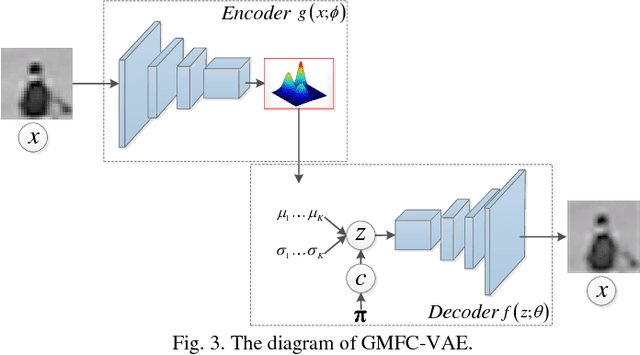

We present a novel end-to-end partially supervised deep learning approach for video anomaly detection and localization using only normal samples. The insight that motivates this study is that the normal samples can be associated with at least one Gaussian component of a Gaussian Mixture Model (GMM), while anomalies either do not belong to any Gaussian component. The method is based on Gaussian Mixture Variational Autoencoder, which can learn feature representations of the normal samples as a Gaussian Mixture Model trained using deep learning. A Fully Convolutional Network (FCN) that does not contain a fully-connected layer is employed for the encoder-decoder structure to preserve relative spatial coordinates between the input image and the output feature map. Based on the joint probabilities of each of the Gaussian mixture components, we introduce a sample energy based method to score the anomaly of image test patches. A two-stream network framework is employed to combine the appearance and motion anomalies, using RGB frames for the former and dynamic flow images, for the latter. We test our approach on two popular benchmarks (UCSD Dataset and Avenue Dataset). The experimental results verify the superiority of our method compared to the state of the arts.
Multi-Path Region-Based Convolutional Neural Network for Accurate Detection of Unconstrained "Hard Faces"
Mar 27, 2017
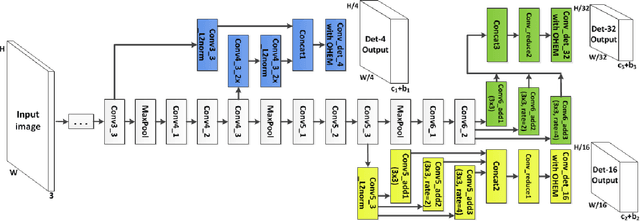
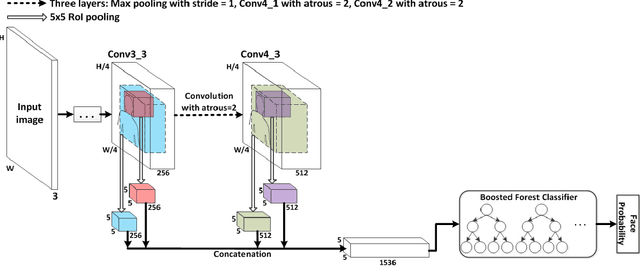

Large-scale variations still pose a challenge in unconstrained face detection. To the best of our knowledge, no current face detection algorithm can detect a face as large as 800 x 800 pixels while simultaneously detecting another one as small as 8 x 8 pixels within a single image with equally high accuracy. We propose a two-stage cascaded face detection framework, Multi-Path Region-based Convolutional Neural Network (MP-RCNN), that seamlessly combines a deep neural network with a classic learning strategy, to tackle this challenge. The first stage is a Multi-Path Region Proposal Network (MP-RPN) that proposes faces at three different scales. It simultaneously utilizes three parallel outputs of the convolutional feature maps to predict multi-scale candidate face regions. The "atrous" convolution trick (convolution with up-sampled filters) and a newly proposed sampling layer for "hard" examples are embedded in MP-RPN to further boost its performance. The second stage is a Boosted Forests classifier, which utilizes deep facial features pooled from inside the candidate face regions as well as deep contextual features pooled from a larger region surrounding the candidate face regions. This step is included to further remove hard negative samples. Experiments show that this approach achieves state-of-the-art face detection performance on the WIDER FACE dataset "hard" partition, outperforming the former best result by 9.6% for the Average Precision.