 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-Guided Attention Networks for Video-Based Person Re-Identification
Paper and Code
Aug 09, 2020
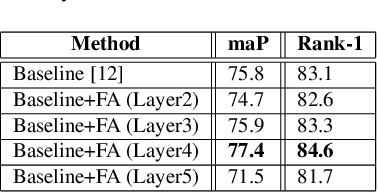

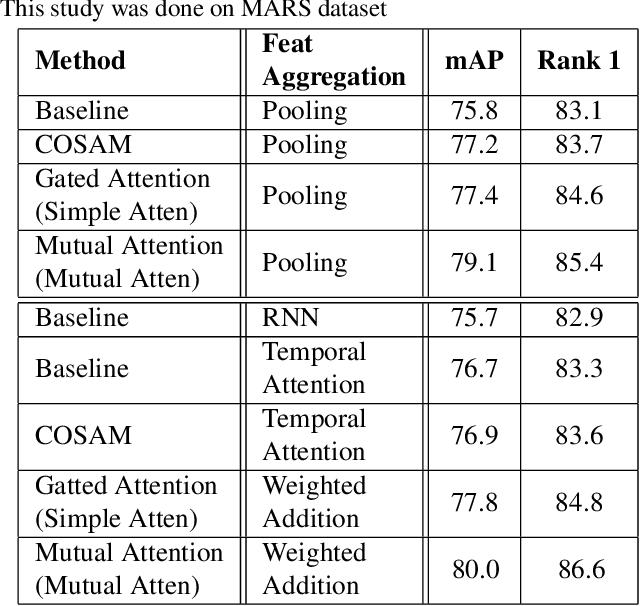
Person Re-Identification (ReID) is an important problem in many video analytics and surveillance applications,where a person's identity must be associated across a distributed network of cameras. Video-based person ReID has recently gained much interest because it can capture discriminant spatio-temporal information that is unavailable for image-based ReID. Despite recent advances, deep learning models for video ReID often fail to leverage this information to improve the robustness of feature representations. In this paper, the motion pattern of a person is explored as an additional cue for ReID. In particular, two different flow-guided attention networks are proposed for fusion with any 2D-CNN backbone, allowing to encode temporal information along with spatial appearance information.Our first proposed network called Gated Attention relies on optical flow to generate gated attention with video-based feature that embed spatially. Hence the proposed framework allows to activate a common set of salient features across multiple frames. In contrast, our second network called Mutual Attention relies on the joint attention between image and optical flow features. This enables spatial attention between both sources of features, across motion and appearance cues. Both methods introduce a feature aggregation method that produce video features by identifying salient spatio-temporal information.Extensive experiments on two challenging video datasets indicate that using the proposed flow-guided spatio-temporal attention networks allows to improve recognition accuracy considerably, outperforming state-of-the-art methods for video-based person ReID. Additionally, our Mutual Attention network is able to process longer frame sequences with a wider range of appearance variations for highly accurate recognition.