 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLOD-TTA: Test-Time Adaptation of Vision-Language Object Detectors
Oct 01, 2025Vision-language object detectors (VLODs) such as YOLO-World and Grounding DINO achieve impressive zero-shot recognition by aligning region proposals with text representations. However, their performance often degrades under domain shift. We introduce VLOD-TTA, a test-time adaptation (TTA) framework for VLODs that leverages dense proposal overlap and image-conditioned prompt scores. First, an IoU-weighted entropy objective is proposed that concentrates adaptation on spatially coherent proposal clusters and reduces confirmation bias from isolated boxes. Second, image-conditioned prompt selection is introduced, which ranks prompts by image-level compatibility and fuses the most informative prompts with the detector logits. Our benchmarking across diverse distribution shifts -- including stylized domains, driving scenes, low-light conditions, and common corruptions -- shows the effectiveness of our method on two state-of-the-art VLODs, YOLO-World and Grounding DINO, with consistent improvements over the zero-shot and TTA baselines. Code : https://github.com/imatif17/VLOD-TTA
Low-Rank Expert Merging for Multi-Source Domain Adaptation in Person Re-Identification
Aug 09, 2025Adapting person re-identification (reID) models to new target environments remains a challenging problem that is typically addressed using unsupervised domain adaptation (UDA) methods. Recent works show that when labeled data originates from several distinct sources (e.g., datasets and cameras), considering each source separately and applying multi-source domain adaptation (MSDA) typically yields higher accuracy and robustness compared to blending the sources and performing conventional UDA. However, state-of-the-art MSDA methods learn domain-specific backbone models or require access to source domain data during adaptation, resulting in significant growth in training parameters and computational cost. In this paper, a Source-free Adaptive Gated Experts (SAGE-reID) method is introduced for person reID. Our SAGE-reID is a cost-effective, source-free MSDA method that first trains individual source-specific low-rank adapters (LoRA) through source-free UDA. Next, a lightweight gating network is introduced and trained to dynamically assign optimal merging weights for fusion of LoRA experts, enabling effective cross-domain knowledge transfer. While the number of backbone parameters remains constant across source domains, LoRA experts scale linearly but remain negligible in size (<= 2% of the backbone), reducing both the memory consumption and risk of overfitting. Extensive experiments conducted on three challenging benchmarks: Market-1501, DukeMTMC-reID, and MSMT17 indicate that SAGE-reID outperforms state-of-the-art methods while being computationally efficient.
Visual Modality Prompt for Adapting Vision-Language Object Detectors
Dec 01, 2024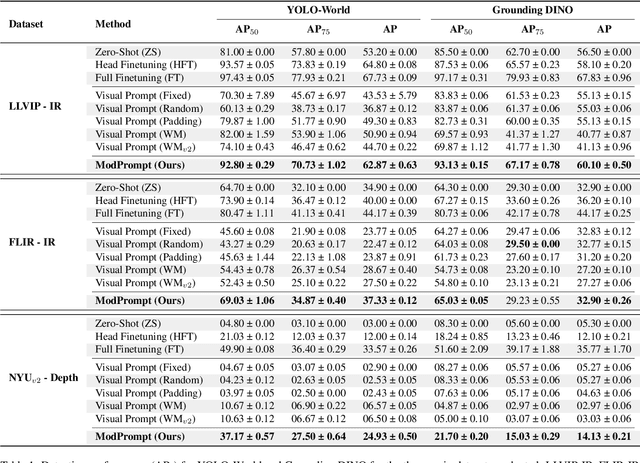

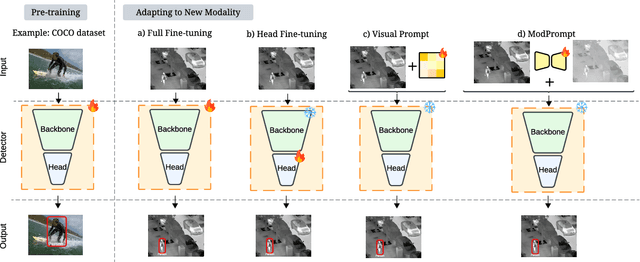
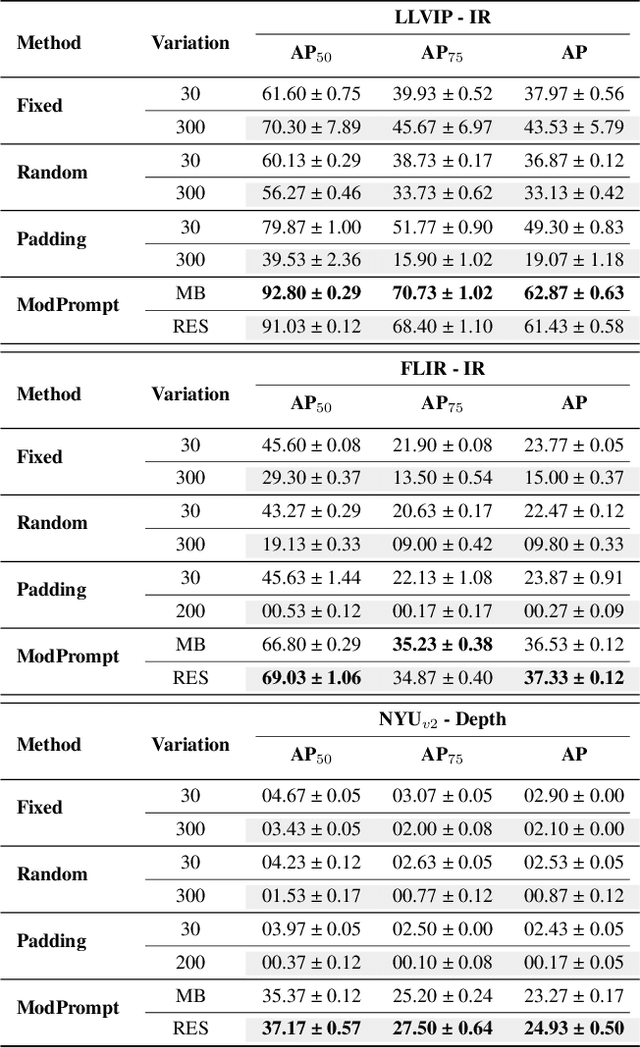
The zero-shot performance of object detectors degrades when tested on different modalities, such as infrared and depth. While recent work has explored image translation techniques to adapt detectors to new modalities, these methods are limited to a single modality and apply only to traditional detectors. Recently, vision-language detectors, such as YOLO-World and Grounding DINO, have shown promising zero-shot capabilities, however, they have not yet been adapted for other visual modalities. Traditional fine-tuning approaches tend to compromise the zero-shot capabilities of the detectors. The visual prompt strategies commonly used for classification with vision-language models apply the same linear prompt translation to each image making them less effective. To address these limitations, we propose ModPrompt, a visual prompt strategy to adapt vision-language detectors to new modalities without degrading zero-shot performance. In particular, an encoder-decoder visual prompt strategy is proposed, further enhanced by the integration of inference-friendly task residuals, facilitating more robust adaptation. Empirically, we benchmark our method for modality adaptation on two vision-language detectors, YOLO-World and Grounding DINO, and on challenging infrared (LLVIP, FLIR) and depth (NYUv2) data, achieving performance comparable to full fine-tuning while preserving the model's zero-shot capability. Our code is available at: https://github.com/heitorrapela/ModPrompt
Attention-based Class-Conditioned Alignment for Multi-Source Domain Adaptive Object Detection
Mar 14, 2024



Domain adaptation methods for object detection (OD) strive to mitigate the impact of distribution shifts by promoting feature alignment across source and target domains. Multi-source domain adaptation (MSDA) allows leveraging multiple annotated source datasets, and unlabeled target data to improve the accuracy and robustness of the detection model. Most state-of-the-art MSDA methods for OD perform feature alignment in a class-agnostic manner. This is challenging since the objects have unique modal information due to variations in object appearance across domains. A recent prototype-based approach proposed a class-wise alignment, yet it suffers from error accumulation due to noisy pseudo-labels which can negatively affect adaptation with imbalanced data. To overcome these limitations, we propose an attention-based class-conditioned alignment scheme for MSDA that aligns instances of each object category across domains. In particular, an attention module coupled with an adversarial domain classifier allows learning domain-invariant and class-specific instance representations. Experimental results on multiple benchmarking MSDA datasets indicate that our method outperforms the state-of-the-art methods and is robust to class imbalance. Our code is available at https://github.com/imatif17/ACIA.
Multi-Source Domain Adaptation for Object Detection with Prototype-based Mean-teacher
Sep 26, 2023



Adapting visual object detectors to operational target domains is a challenging task, commonly achieved using unsupervised domain adaptation (UDA) methods. When the labeled dataset is coming from multiple source domains, treating them as separate domains and performing a multi-source domain adaptation (MSDA) improves the accuracy and robustness over mixing these source domains and performing a UDA, as observed by recent studies in MSDA. Existing MSDA methods learn domain invariant and domain-specific parameters (for each source domain) for the adaptation. However, unlike single-source UDA methods, learning domain-specific parameters makes them grow significantly proportional to the number of source domains used. This paper proposes a novel MSDA method called Prototype-based Mean-Teacher (PMT), which uses class prototypes instead of domain-specific subnets to preserve domain-specific information. These prototypes are learned using a contrastive loss, aligning the same categories across domains and separating different categories far apart. Because of the use of prototypes, the parameter size of our method does not increase significantly with the number of source domains, thus reducing memory issues and possible overfitting. Empirical studies show PMT outperforms state-of-the-art MSDA methods on several challenging object detection datasets.
Knowledge Distillation Methods for Efficient Unsupervised Adaptation Across Multiple Domains
Jan 18, 2021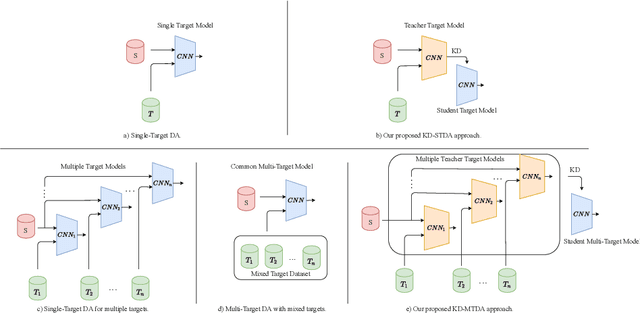
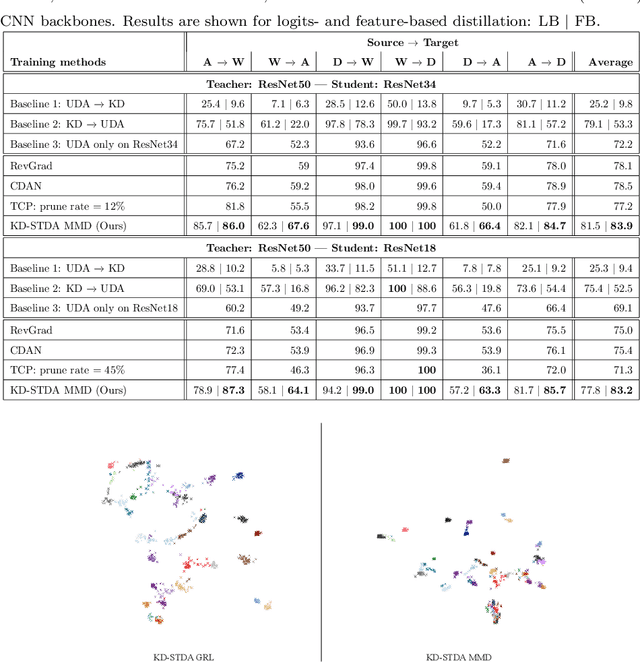
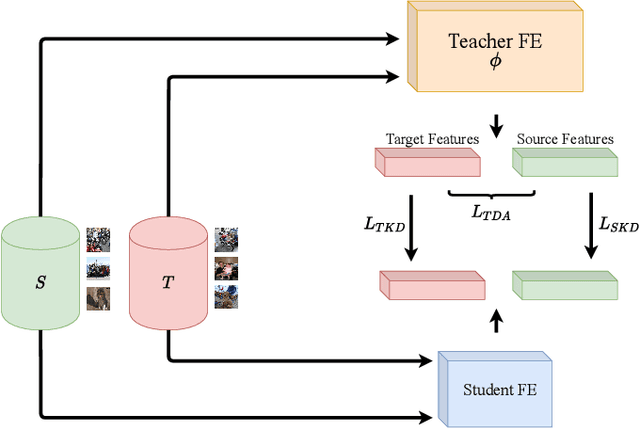
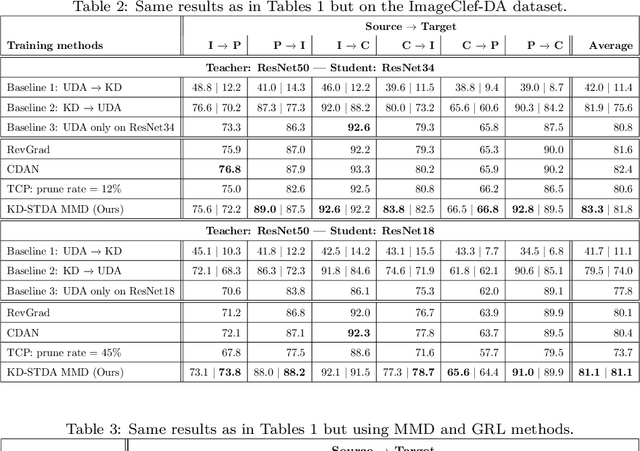
Beyond the complexity of CNNs that require training on large annotated datasets, the domain shift between design and operational data has limited the adoption of CNNs in many real-world applications. For instance, in person re-identification, videos are captured over a distributed set of cameras with non-overlapping viewpoints. The shift between the source (e.g. lab setting) and target (e.g. cameras) domains may lead to a significant decline in recognition accuracy. Additionally, state-of-the-art CNNs may not be suitable for such real-time applications given their computational requirements. Although several techniques have recently been proposed to address domain shift problems through unsupervised domain adaptation (UDA), or to accelerate/compress CNNs through knowledge distillation (KD), we seek to simultaneously adapt and compress CNNs to generalize well across multiple target domains. In this paper, we propose a progressive KD approach for unsupervised single-target DA (STDA) and multi-target DA (MTDA) of CNNs. Our method for KD-STDA adapts a CNN to a single target domain by distilling from a larger teacher CNN, trained on both target and source domain data in order to maintain its consistency with a common representation. Our proposed approach is compared against state-of-the-art methods for compression and STDA of CNNs on the Office31 and ImageClef-DA image classification datasets. It is also compared against state-of-the-art methods for MTDA on Digits, Office31, and OfficeHome. In both settings -- KD-STDA and KD-MTDA -- results indicate that our approach can achieve the highest level of accuracy across target domains, while requiring a comparable or lower CNN complexity.