 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Class-Conditioned Alignment for Multi-Source Domain Adaptive Object Detection
Mar 14, 2024



Domain adaptation methods for object detection (OD) strive to mitigate the impact of distribution shifts by promoting feature alignment across source and target domains. Multi-source domain adaptation (MSDA) allows leveraging multiple annotated source datasets, and unlabeled target data to improve the accuracy and robustness of the detection model. Most state-of-the-art MSDA methods for OD perform feature alignment in a class-agnostic manner. This is challenging since the objects have unique modal information due to variations in object appearance across domains. A recent prototype-based approach proposed a class-wise alignment, yet it suffers from error accumulation due to noisy pseudo-labels which can negatively affect adaptation with imbalanced data. To overcome these limitations, we propose an attention-based class-conditioned alignment scheme for MSDA that aligns instances of each object category across domains. In particular, an attention module coupled with an adversarial domain classifier allows learning domain-invariant and class-specific instance representations. Experimental results on multiple benchmarking MSDA datasets indicate that our method outperforms the state-of-the-art methods and is robust to class imbalance. Our code is available at https://github.com/imatif17/ACIA.
Multi-Source Domain Adaptation for Object Detection with Prototype-based Mean-teacher
Sep 26, 2023



Adapting visual object detectors to operational target domains is a challenging task, commonly achieved using unsupervised domain adaptation (UDA) methods. When the labeled dataset is coming from multiple source domains, treating them as separate domains and performing a multi-source domain adaptation (MSDA) improves the accuracy and robustness over mixing these source domains and performing a UDA, as observed by recent studies in MSDA. Existing MSDA methods learn domain invariant and domain-specific parameters (for each source domain) for the adaptation. However, unlike single-source UDA methods, learning domain-specific parameters makes them grow significantly proportional to the number of source domains used. This paper proposes a novel MSDA method called Prototype-based Mean-Teacher (PMT), which uses class prototypes instead of domain-specific subnets to preserve domain-specific information. These prototypes are learned using a contrastive loss, aligning the same categories across domains and separating different categories far apart. Because of the use of prototypes, the parameter size of our method does not increase significantly with the number of source domains, thus reducing memory issues and possible overfitting. Empirical studies show PMT outperforms state-of-the-art MSDA methods on several challenging object detection datasets.
Density Crop-guided Semi-supervised Object Detection in Aerial Images
Aug 09, 2023



One of the important bottlenecks in training modern object detectors is the need for labeled images where bounding box annotations have to be produced for each object present in the image. This bottleneck is further exacerbated in aerial images where the annotators have to label small objects often distributed in clusters on high-resolution images. In recent days, the mean-teacher approach trained with pseudo-labels and weak-strong augmentation consistency is gaining popularity for semi-supervised object detection. However, a direct adaptation of such semi-supervised detectors for aerial images where small clustered objects are often present, might not lead to optimal results. In this paper, we propose a density crop-guided semi-supervised detector that identifies the cluster of small objects during training and also exploits them to improve performance at inference. During training, image crops of clusters identified from labeled and unlabeled images are used to augment the training set, which in turn increases the chance of detecting small objects and creating good pseudo-labels for small objects on the unlabeled images. During inference, the detector is not only able to detect the objects of interest but also regions with a high density of small objects (density crops) so that detections from the input image and detections from image crops are combined, resulting in an overall more accurate object prediction, especially for small objects. Empirical studies on the popular benchmarks of VisDrone and DOTA datasets show the effectiveness of our density crop-guided semi-supervised detector with an average improvement of more than 2\% over the basic mean-teacher method in COCO style AP. Our code is available at: https://github.com/akhilpm/DroneSSOD.
Cascaded Zoom-in Detector for High Resolution Aerial Images
Mar 15, 2023Detecting objects in aerial images is challenging because they are typically composed of crowded small objects distributed non-uniformly over high-resolution images. Density cropping is a widely used method to improve this small object detection where the crowded small object regions are extracted and processed in high resolution. However, this is typically accomplished by adding other learnable components, thus complicating the training and inference over a standard detection process. In this paper, we propose an efficient Cascaded Zoom-in (CZ) detector that re-purposes the detector itself for density-guided training and inference. During training, density crops are located, labeled as a new class, and employed to augment the training dataset. During inference, the density crops are first detected along with the base class objects, and then input for a second stage of inference. This approach is easily integrated into any detector, and creates no significant change in the standard detection process, like the uniform cropping approach popular in aerial image detection. Experimental results on the aerial images of the challenging VisDrone and DOTA datasets verify the benefits of the proposed approach. The proposed CZ detector also provides state-of-the-art results over uniform cropping and other density cropping methods on the VisDrone dataset, increasing the detection mAP of small objects by more than 3 points.
Semi-Weakly Supervised Object Detection by Sampling Pseudo Ground-Truth Boxes
Apr 01, 2022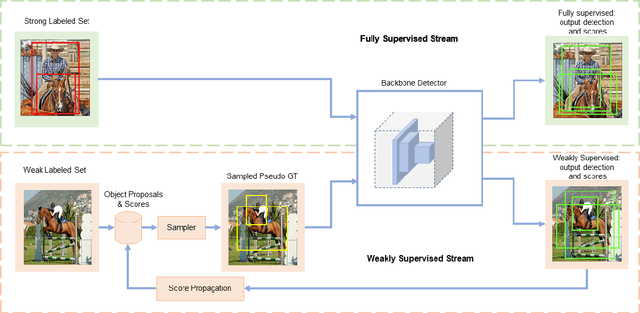

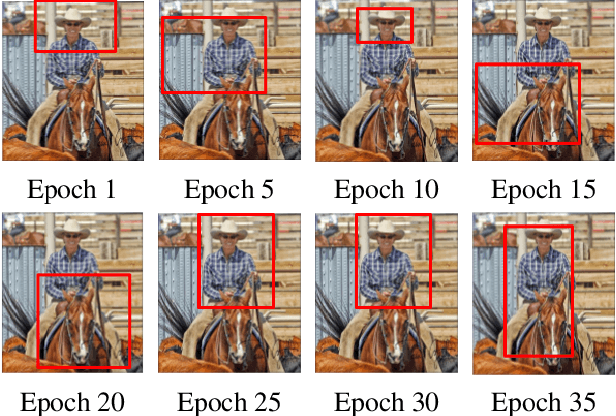

Semi- and weakly-supervised learning have recently attracted considerable attention in the object detection literature since they can alleviate the cost of annotation needed to successfully train deep learning models. State-of-art approaches for semi-supervised learning rely on student-teacher models trained using a multi-stage process, and considerable data augmentation. Custom networks have been developed for the weakly-supervised setting, making it difficult to adapt to different detectors. In this paper, a weakly semi-supervised training method is introduced that reduces these training challenges, yet achieves state-of-the-art performance by leveraging only a small fraction of fully-labeled images with information in weakly-labeled images. In particular, our generic sampling-based learning strategy produces pseudo-ground-truth (GT) bounding box annotations in an online fashion, eliminating the need for multi-stage training, and student-teacher network configurations. These pseudo GT boxes are sampled from weakly-labeled images based on the categorical score of object proposals accumulated via a score propagation process. Empirical results on the Pascal VOC dataset, indicate that the proposed approach improves performance by 5.0% when using VOC 2007 as fully-labeled, and VOC 2012 as weak-labeled data. Also, with 5-10% fully annotated images, we observed an improvement of more than 10% in mAP, showing that a modest investment in image-level annotation, can substantially improve detection performance.
Unsupervised MKL in Multi-layer Kernel Machines
Nov 26, 2021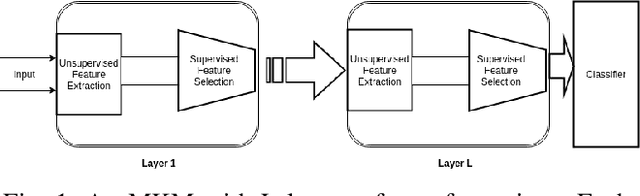


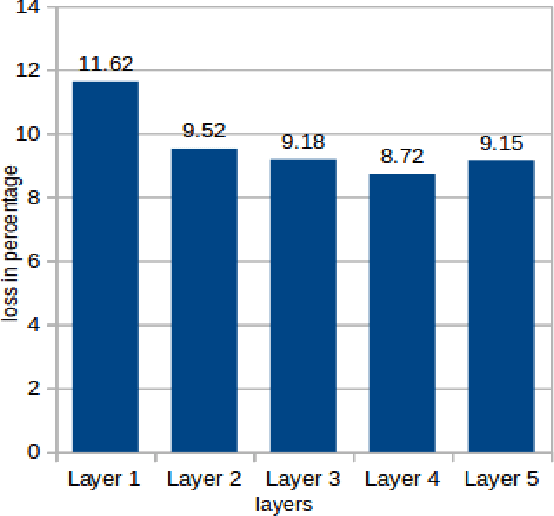
Kernel based Deep Learning using multi-layer kernel machines(MKMs) was proposed by Y.Cho and L.K. Saul in \cite{saul}. In MKMs they used only one kernel(arc-cosine kernel) at a layer for the kernel PCA-based feature extraction. We propose to use multiple kernels in each layer by taking a convex combination of many kernels following an unsupervised learning strategy. Empirical study is conducted on \textit{mnist-back-rand}, \textit{mnist-back-image} and \textit{mnist-rot-back-image} datasets generated by adding random noise in the image background of MNIST dataset. Experimental results indicate that using MKL in MKMs earns a better representation of the raw data and improves the classifier performance.
Convolutional STN for Weakly Supervised Object Localization and Beyond
Dec 03, 2019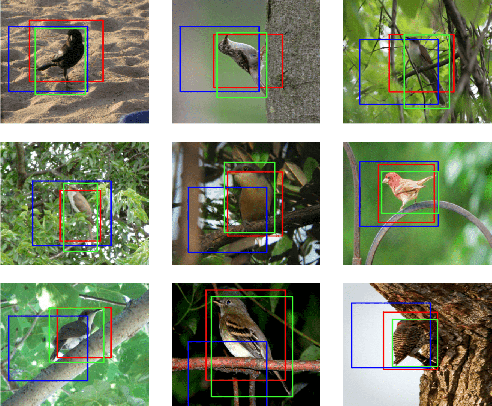

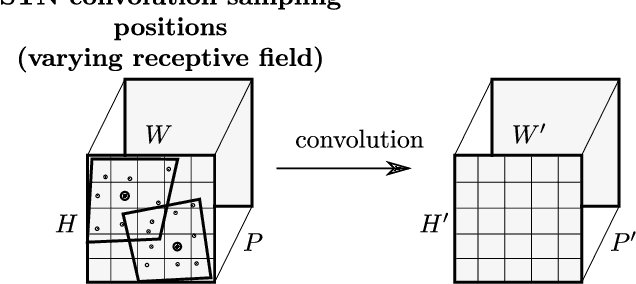
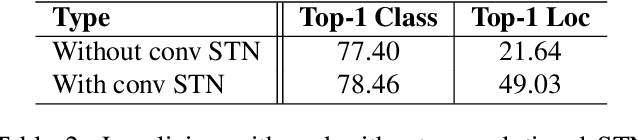
Weakly-supervised object localization is a challenging task in which the object of interest should be localized while learning its appearance. State-of-the-art methods recycle the architecture of a standard CNN by using the activation maps of the last layer for localizing the object. While this approach is simple and works relatively well, object localization relies on different features than classification, thus, a specialized localization mechanism is required during training to improve performance. In this paper we propose a convolutional, multi-scale spatial localization network that provides accurate localization for the object of interest. Experimental results on CUB-200-2011 and ImageNet datasets show the improvements of our proposed approach w.r.t. state-of-the-art methods.