 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutosen: improving automatic wifi human sensing through cross-modal autoencoder
Jan 08, 2024WiFi human sensing is highly regarded for its low-cost and privacy advantages in recognizing human activities. However, its effectiveness is largely confined to controlled, single-user, line-of-sight settings, limited by data collection complexities and the scarcity of labeled datasets. Traditional cross-modal methods, aimed at mitigating these limitations by enabling self-supervised learning without labeled data, struggle to extract meaningful features from amplitude-phase combinations. In response, we introduce AutoSen, an innovative automatic WiFi sensing solution that departs from conventional approaches. AutoSen establishes a direct link between amplitude and phase through automated cross-modal autoencoder learning. This autoencoder efficiently extracts valuable features from unlabeled CSI data, encompassing amplitude and phase information while eliminating their respective unique noises. These features are then leveraged for specific tasks using few-shot learning techniques. AutoSen's performance is rigorously evaluated on a publicly accessible benchmark dataset, demonstrating its exceptional capabilities in automatic WiFi sensing through the extraction of comprehensive cross-modal features.
WiFi-based Spatiotemporal Human Action Perception
Jun 20, 2022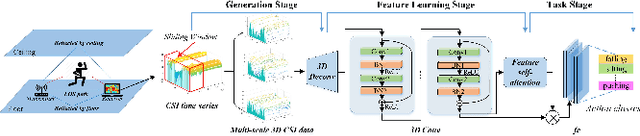
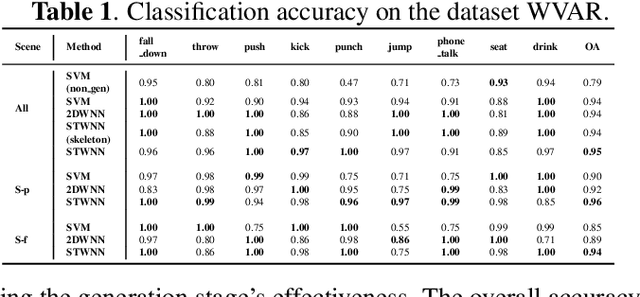
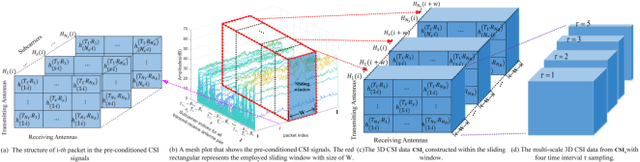
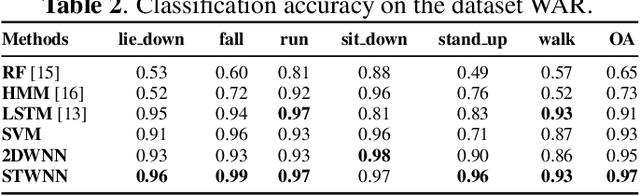
WiFi-based sensing for human activity recognition (HAR) has recently become a hot topic as it brings great benefits when compared with video-based HAR, such as eliminating the demands of line-of-sight (LOS) and preserving privacy. Making the WiFi signals to 'see' the action, however, is quite coarse and thus still in its infancy. An end-to-end spatiotemporal WiFi signal neural network (STWNN) is proposed to enable WiFi-only sensing in both line-of-sight and non-line-of-sight scenarios. Especially, the 3D convolution module is able to explore the spatiotemporal continuity of WiFi signals, and the feature self-attention module can explicitly maintain dominant features. In addition, a novel 3D representation for WiFi signals is designed to preserve multi-scale spatiotemporal information. Furthermore, a small wireless-vision dataset (WVAR) is synchronously collected to extend the potential of STWNN to 'see' through occlusions. Quantitative and qualitative results on WVAR and the other three public benchmark datasets demonstrate the effectiveness of our approach on both accuracy and shift consistency.
A Wireless-Vision Dataset for Privacy Preserving Human Activity Recognition
May 24, 2022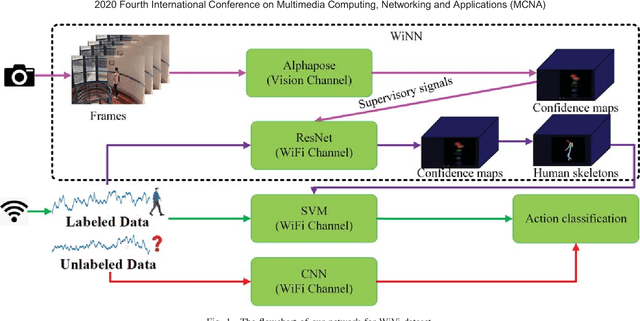

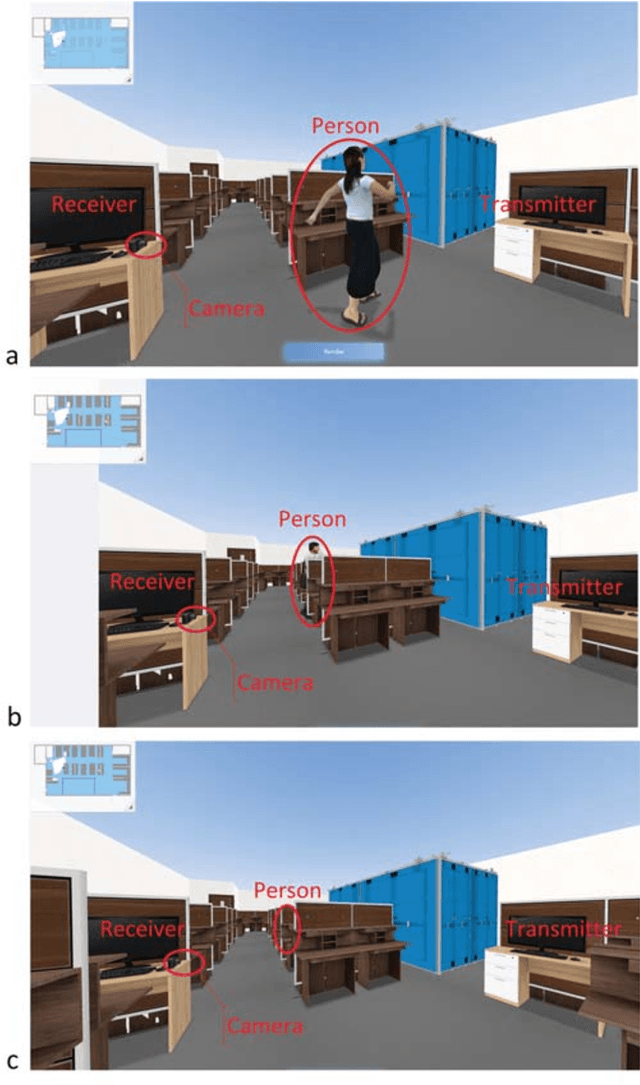
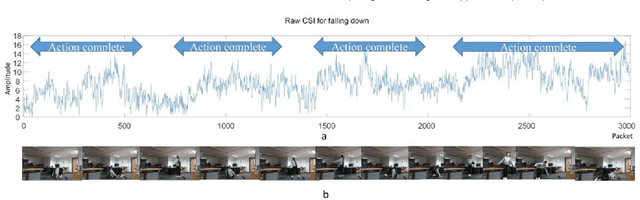
Human Activity Recognition (HAR) has recently received remarkable attention in numerous applications such as assisted living and remote monitoring. Existing solutions based on sensors and vision technologies have obtained achievements but still suffering from considerable limitations in the environmental requirement. Wireless signals like WiFi-based sensing have emerged as a new paradigm since it is convenient and not restricted in the environment. In this paper, a new WiFi-based and video-based neural network (WiNN) is proposed to improve the robustness of activity recognition where the synchronized video serves as the supplement for the wireless data. Moreover, a wireless-vision benchmark (WiVi) is collected for 9 class actions recognition in three different visual conditions, including the scenes without occlusion, with partial occlusion, and with full occlusion. Both machine learning methods - support vector machine (SVM) as well as deep learning methods are used for the accuracy verification of the data set. Our results show that WiVi data set satisfies the primary demand and all three branches in the proposed pipeline keep more than $80\%$ of activity recognition accuracy over multiple action segmentation from 1s to 3s. In particular, WiNN is the most robust method in terms of all the actions on three action segmentation compared to the others.
GraSens: A Gabor Residual Anti-aliasing Sensing Framework for Action Recognition using WiFi
May 24, 2022
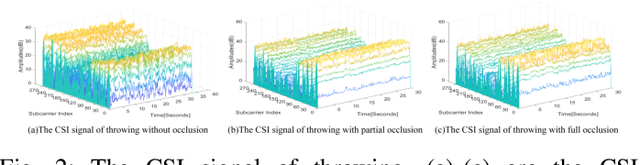


WiFi-based human action recognition (HAR) has been regarded as a promising solution in applications such as smart living and remote monitoring due to the pervasive and unobtrusive nature of WiFi signals. However, the efficacy of WiFi signals is prone to be influenced by the change in the ambient environment and varies over different sub-carriers. To remedy this issue, we propose an end-to-end Gabor residual anti-aliasing sensing network (GraSens) to directly recognize the actions using the WiFi signals from the wireless devices in diverse scenarios. In particular, a new Gabor residual block is designed to address the impact of the changing surrounding environment with a focus on learning reliable and robust temporal-frequency representations of WiFi signals. In each block, the Gabor layer is integrated with the anti-aliasing layer in a residual manner to gain the shift-invariant features. Furthermore, fractal temporal and frequency self-attention are proposed in a joint effort to explicitly concentrate on the efficacy of WiFi signals and thus enhance the quality of output features scattered in different subcarriers. Experimental results throughout our wireless-vision action recognition dataset (WVAR) and three public datasets demonstrate that our proposed GraSens scheme outperforms state-of-the-art methods with respect to recognition accuracy.