 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL based Beamforming Optimization for 3D Pinching Antenna assisted ISAC Systems
Jan 28, 2026In this paper, a three-dimensional (3D) deployment scheme of pinching antenna array is proposed, aiming to enhances the performance of integrated sensing and communication (ISAC) systems. To fully realize the potential of 3D deployment, a joint antenna positioning, time allocation and transmit power optimization problem is formulated to maximize the sum communication rate with the constraints of target sensing rates and system energy. To solve the sum rate maximization problem, we propose a heterogeneous graph neural network based reinforcement learning (HGRL) algorithm. Simulation results prove that 3D deployment of pinching antenna array outperforms 1D and 2D counterparts in ISAC systems. Moreover, the proposed HGRL algorithm surpasses other baselines in both performance and convergence speed due to the advanced observation construction of the environment.
Deep Learning based Three-stage Solution for ISAC Beamforming Optimization
Jan 28, 2026In this paper, a general ISAC system where the base station (BS) communicates with multiple users and performs target detection is considered. Then, a sum communication rate maximization problem is formulated, subjected to the constraints of transmit power and the minimum sensing rates of users. To solve this problem, we develop a framework that leverages deep learning algorithms to provide a three-stage solution for ISAC beamforming. The three-stage beamforming optimization solution includes three modules: 1) an unsupervised learning based feature extraction algorithm is proposed to extract fixed-size latent features while keeping its essential information from the variable channel state information (CSI); 2) a reinforcement learning (RL) based beampattern optimization algorithm is proposed to search the desired beampattern according to the extracted features; 3) a supervised learning based beamforming reconstruction algorithm is proposed to reconstruct the beamforming vector from beampattern given by the RL agent. Simulation results demonstrate that the proposed three-stage solution outperforms the baseline RL algorithm by optimizing the intuitional beampattern rather than beamforming.
GPU-accelerated Multi-relational Parallel Graph Retrieval for Web-scale Recommendations
Feb 17, 2025Web recommendations provide personalized items from massive catalogs for users, which rely heavily on retrieval stages to trade off the effectiveness and efficiency of selecting a small relevant set from billion-scale candidates in online digital platforms. As one of the largest Chinese search engine and news feed providers, Baidu resorts to Deep Neural Network (DNN) and graph-based Approximate Nearest Neighbor Search (ANNS) algorithms for accurate relevance estimation and efficient search for relevant items. However, current retrieval at Baidu fails in comprehensive user-item relational understanding due to dissected interaction modeling, and performs inefficiently in large-scale graph-based ANNS because of suboptimal traversal navigation and the GPU computational bottleneck under high concurrency. To this end, we propose a GPU-accelerated Multi-relational Parallel Graph Retrieval (GMP-GR) framework to achieve effective yet efficient retrieval in web-scale recommendations. First, we propose a multi-relational user-item relevance metric learning method that unifies diverse user behaviors through multi-objective optimization and employs a self-covariant loss to enhance pathfinding performance. Second, we develop a hierarchical parallel graph-based ANNS to boost graph retrieval throughput, which conducts breadth-depth-balanced searches on a large-scale item graph and cost-effectively handles irregular neural computation via adaptive aggregation on GPUs. In addition, we integrate system optimization strategies in the deployment of GMP-GR in Baidu. Extensive experiments demonstrate the superiority of GMP-GR in retrieval accuracy and efficiency. Deployed across more than twenty applications at Baidu, GMP-GR serves hundreds of millions of users with a throughput exceeding one hundred million requests per second.
Controllable Edge-Type-Specific Interpretation in Multi-Relational Graph Neural Networks for Drug Response Prediction
Sep 03, 2024
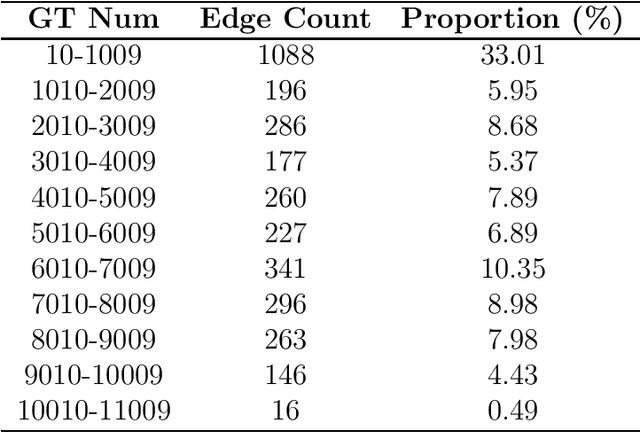
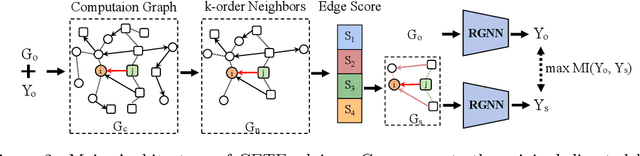
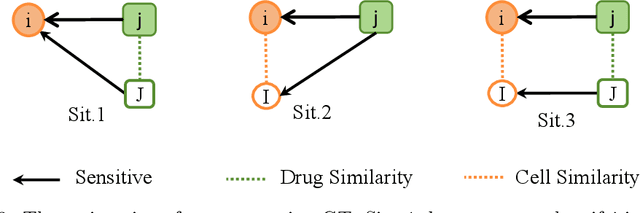
Graph Neural Networks have been widely applied in critical decision-making areas that demand interpretable predictions, leading to the flourishing development of interpretability algorithms. However, current graph interpretability algorithms tend to emphasize generality and often overlook biological significance, thereby limiting their applicability in predicting cancer drug responses. In this paper, we propose a novel post-hoc interpretability algorithm for cancer drug response prediction, CETExplainer, which incorporates a controllable edge-type-specific weighting mechanism. It considers the mutual information between subgraphs and predictions, proposing a structural scoring approach to provide fine-grained, biologically meaningful explanations for predictive models. We also introduce a method for constructing ground truth based on real-world datasets to quantitatively evaluate the proposed interpretability algorithm. Empirical analysis on the real-world dataset demonstrates that CETExplainer achieves superior stability and improves explanation quality compared to leading algorithms, thereby offering a robust and insightful tool for cancer drug prediction.
DRExplainer: Quantifiable Interpretability in Drug Response Prediction with Directed Graph Convolutional Network
Aug 22, 2024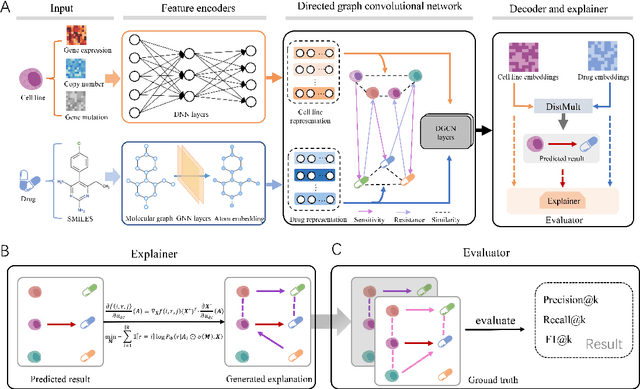
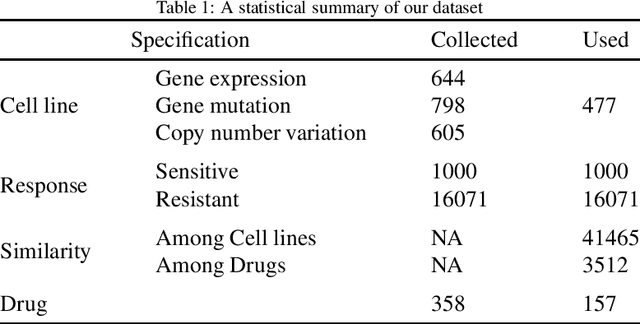

Predicting the response of a cancer cell line to a therapeutic drug is pivotal for personalized medicine. Despite numerous deep learning methods that have been developed for drug response prediction, integrating diverse information about biological entities and predicting the directional response remain major challenges. Here, we propose a novel interpretable predictive model, DRExplainer, which leverages a directed graph convolutional network to enhance the prediction in a directed bipartite network framework. DRExplainer constructs a directed bipartite network integrating multi-omics profiles of cell lines, the chemical structure of drugs and known drug response to achieve directed prediction. Then, DRExplainer identifies the most relevant subgraph to each prediction in this directed bipartite network by learning a mask, facilitating critical medical decision-making. Additionally, we introduce a quantifiable method for model interpretability that leverages a ground truth benchmark dataset curated from biological features. In computational experiments, DRExplainer outperforms state-of-the-art predictive methods and another graph-based explanation method under the same experimental setting. Finally, the case studies further validate the interpretability and the effectiveness of DRExplainer in predictive novel drug response. Our code is available at: https://github.com/vshy-dream/DRExplainer.
Autosen: improving automatic wifi human sensing through cross-modal autoencoder
Jan 08, 2024WiFi human sensing is highly regarded for its low-cost and privacy advantages in recognizing human activities. However, its effectiveness is largely confined to controlled, single-user, line-of-sight settings, limited by data collection complexities and the scarcity of labeled datasets. Traditional cross-modal methods, aimed at mitigating these limitations by enabling self-supervised learning without labeled data, struggle to extract meaningful features from amplitude-phase combinations. In response, we introduce AutoSen, an innovative automatic WiFi sensing solution that departs from conventional approaches. AutoSen establishes a direct link between amplitude and phase through automated cross-modal autoencoder learning. This autoencoder efficiently extracts valuable features from unlabeled CSI data, encompassing amplitude and phase information while eliminating their respective unique noises. These features are then leveraged for specific tasks using few-shot learning techniques. AutoSen's performance is rigorously evaluated on a publicly accessible benchmark dataset, demonstrating its exceptional capabilities in automatic WiFi sensing through the extraction of comprehensive cross-modal features.
Credible Remote Sensing Scene Classification Using Evidential Fusion on Aerial-Ground Dual-view Images
Jan 02, 2023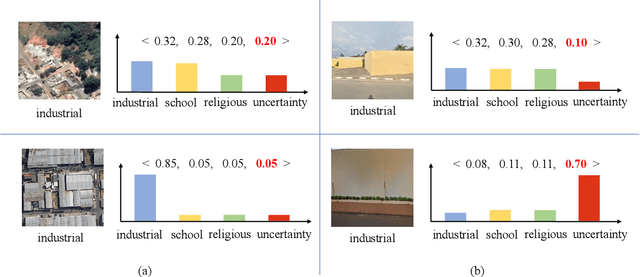



Due to their ability to offer more comprehensive information than data from a single view, multi-view (multi-source, multi-modal, multi-perspective, etc.) data are being used more frequently in remote sensing tasks. However, as the number of views grows, the issue of data quality becomes more apparent, limiting the potential benefits of multi-view data. Although recent deep neural network (DNN) based models can learn the weight of data adaptively, a lack of research on explicitly quantifying the data quality of each view when fusing them renders these models inexplicable, performing unsatisfactorily and inflexible in downstream remote sensing tasks. To fill this gap, in this paper, evidential deep learning is introduced to the task of aerial-ground dual-view remote sensing scene classification to model the credibility of each view. Specifically, the theory of evidence is used to calculate an uncertainty value which describes the decision-making risk of each view. Based on this uncertainty, a novel decision-level fusion strategy is proposed to ensure that the view with lower risk obtains more weight, making the classification more credible. On two well-known, publicly available datasets of aerial-ground dual-view remote sensing images, the proposed approach achieves state-of-the-art results, demonstrating its effectiveness. The code and datasets of this article are available at the following address: https://github.com/gaopiaoliang/Evidential.
Learning Deep Nets for Gravitational Dynamics with Unknown Disturbance through Physical Knowledge Distillation: Initial Feasibility Study
Oct 04, 2022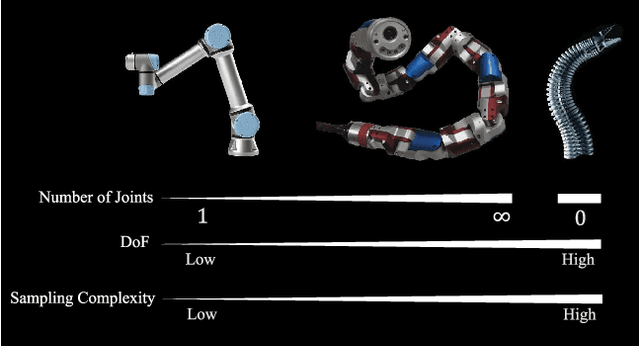
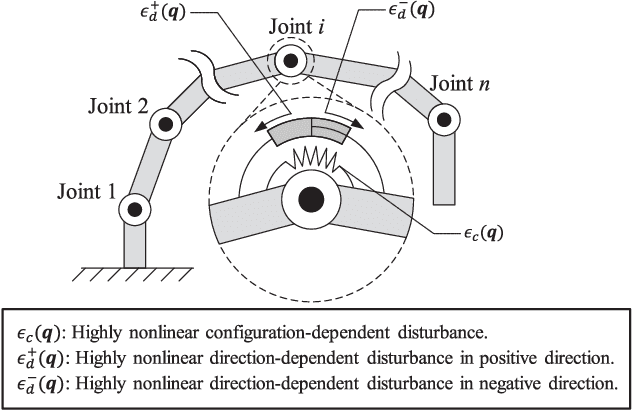
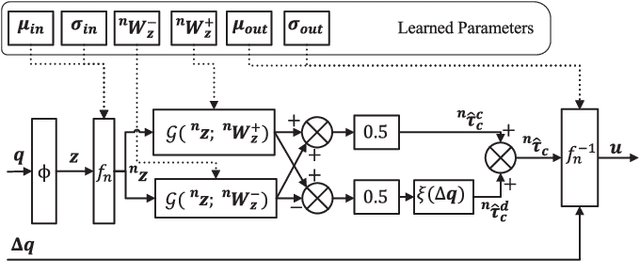

Learning high-performance deep neural networks for dynamic modeling of high Degree-Of-Freedom (DOF) robots remains challenging due to the sampling complexity. Typical unknown system disturbance caused by unmodeled dynamics (such as internal compliance, cables) further exacerbates the problem. In this paper, a novel framework characterized by both high data efficiency and disturbance-adapting capability is proposed to address the problem of modeling gravitational dynamics using deep nets in feedforward gravity compensation control for high-DOF master manipulators with unknown disturbance. In particular, Feedforward Deep Neural Networks (FDNNs) are learned from both prior knowledge of an existing analytical model and observation of the robot system by Knowledge Distillation (KD). Through extensive experiments in high-DOF master manipulators with significant disturbance, we show that our method surpasses a standard Learning-from-Scratch (LfS) approach in terms of data efficiency and disturbance adaptation. Our initial feasibility study has demonstrated the potential of outperforming the analytical teacher model as the training data increases.
JIZHI: A Fast and Cost-Effective Model-As-A-Service System for Web-Scale Online Inference at Baidu
Jun 03, 2021
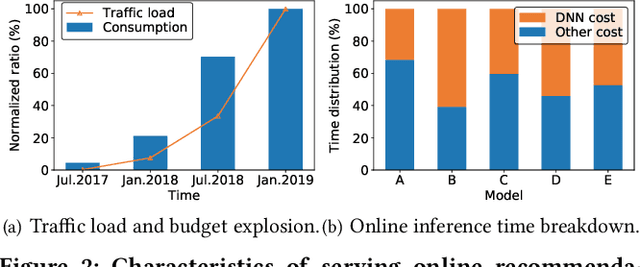
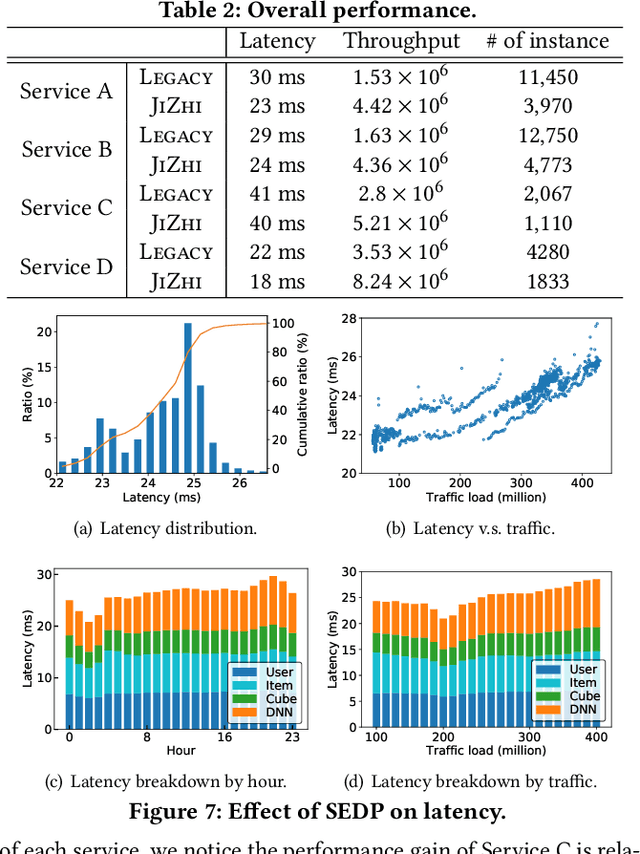
In modern internet industries, deep learning based recommender systems have became an indispensable building block for a wide spectrum of applications, such as search engine, news feed, and short video clips. However, it remains challenging to carry the well-trained deep models for online real-time inference serving, with respect to the time-varying web-scale traffics from billions of users, in a cost-effective manner. In this work, we present JIZHI - a Model-as-a-Service system - that per second handles hundreds of millions of online inference requests to huge deep models with more than trillions of sparse parameters, for over twenty real-time recommendation services at Baidu, Inc. In JIZHI, the inference workflow of every recommendation request is transformed to a Staged Event-Driven Pipeline (SEDP), where each node in the pipeline refers to a staged computation or I/O intensive task processor. With traffics of real-time inference requests arrived, each modularized processor can be run in a fully asynchronized way and managed separately. Besides, JIZHI introduces heterogeneous and hierarchical storage to further accelerate the online inference process by reducing unnecessary computations and potential data access latency induced by ultra-sparse model parameters. Moreover, an intelligent resource manager has been deployed to maximize the throughput of JIZHI over the shared infrastructure by searching the optimal resource allocation plan from historical logs and fine-tuning the load shedding policies over intermediate system feedback. Extensive experiments have been done to demonstrate the advantages of JIZHI from the perspectives of end-to-end service latency, system-wide throughput, and resource consumption. JIZHI has helped Baidu saved more than ten million US dollars in hardware and utility costs while handling 200% more traffics without sacrificing inference efficiency.
Data-driven Optimal Power Flow: A Physics-Informed Machine Learning Approach
May 31, 2020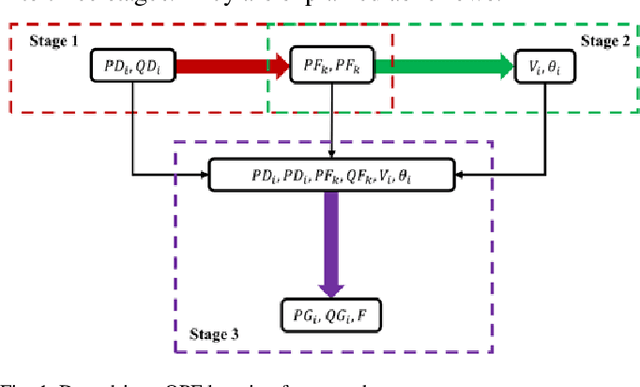
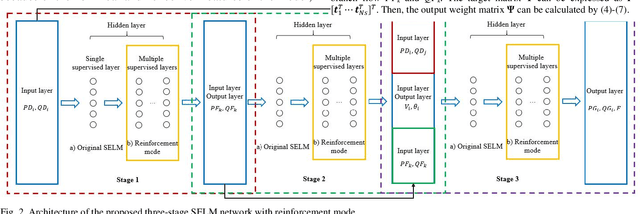
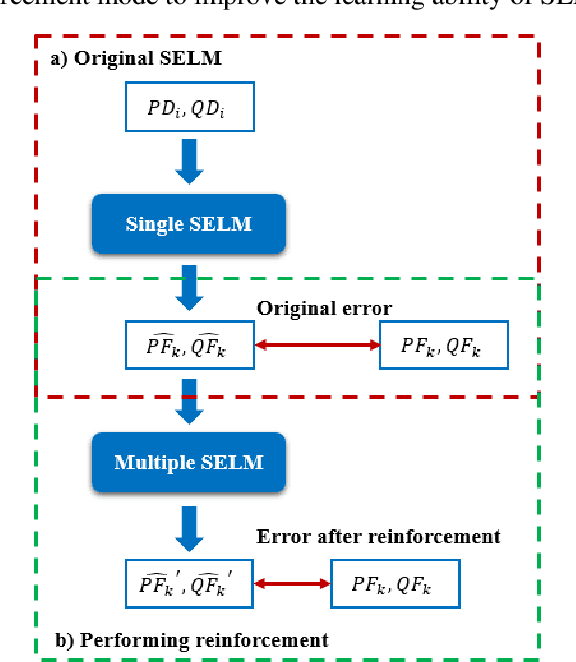
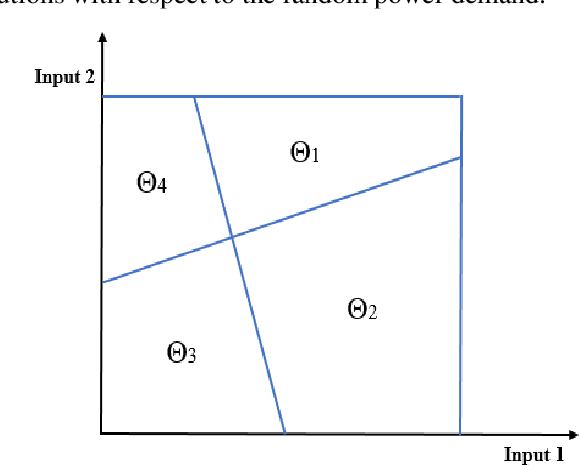
This paper proposes a data-driven approach for optimal power flow (OPF) based on the stacked extreme learning machine (SELM) framework. SELM has a fast training speed and does not require the time-consuming parameter tuning process compared with the deep learning algorithms. However, the direct application of SELM for OPF is not tractable due to the complicated relationship between the system operating status and the OPF solutions. To this end, a data-driven OPF regression framework is developed that decomposes the OPF model features into three stages. This not only reduces the learning complexity but also helps correct the learning bias. A sample pre-classification strategy based on active constraint identification is also developed to achieve enhanced feature attractions. Numerical results carried out on IEEE and Polish benchmark systems demonstrate that the proposed method outperforms other alternatives. It is also shown that the proposed method can be easily extended to address different test systems by adjusting only a few hyperparameters.