 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-accelerated Multi-relational Parallel Graph Retrieval for Web-scale Recommendations
Feb 17, 2025Web recommendations provide personalized items from massive catalogs for users, which rely heavily on retrieval stages to trade off the effectiveness and efficiency of selecting a small relevant set from billion-scale candidates in online digital platforms. As one of the largest Chinese search engine and news feed providers, Baidu resorts to Deep Neural Network (DNN) and graph-based Approximate Nearest Neighbor Search (ANNS) algorithms for accurate relevance estimation and efficient search for relevant items. However, current retrieval at Baidu fails in comprehensive user-item relational understanding due to dissected interaction modeling, and performs inefficiently in large-scale graph-based ANNS because of suboptimal traversal navigation and the GPU computational bottleneck under high concurrency. To this end, we propose a GPU-accelerated Multi-relational Parallel Graph Retrieval (GMP-GR) framework to achieve effective yet efficient retrieval in web-scale recommendations. First, we propose a multi-relational user-item relevance metric learning method that unifies diverse user behaviors through multi-objective optimization and employs a self-covariant loss to enhance pathfinding performance. Second, we develop a hierarchical parallel graph-based ANNS to boost graph retrieval throughput, which conducts breadth-depth-balanced searches on a large-scale item graph and cost-effectively handles irregular neural computation via adaptive aggregation on GPUs. In addition, we integrate system optimization strategies in the deployment of GMP-GR in Baidu. Extensive experiments demonstrate the superiority of GMP-GR in retrieval accuracy and efficiency. Deployed across more than twenty applications at Baidu, GMP-GR serves hundreds of millions of users with a throughput exceeding one hundred million requests per second.
JIZHI: A Fast and Cost-Effective Model-As-A-Service System for Web-Scale Online Inference at Baidu
Jun 03, 2021
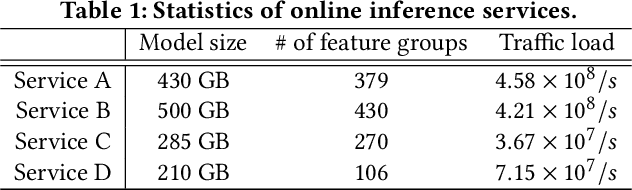
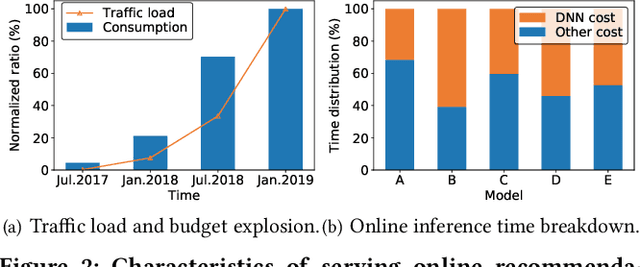
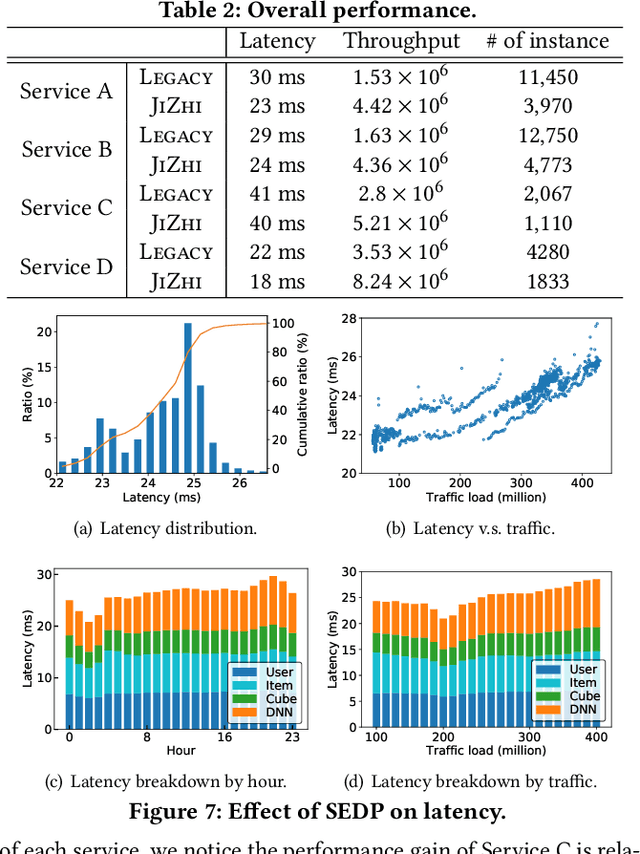
In modern internet industries, deep learning based recommender systems have became an indispensable building block for a wide spectrum of applications, such as search engine, news feed, and short video clips. However, it remains challenging to carry the well-trained deep models for online real-time inference serving, with respect to the time-varying web-scale traffics from billions of users, in a cost-effective manner. In this work, we present JIZHI - a Model-as-a-Service system - that per second handles hundreds of millions of online inference requests to huge deep models with more than trillions of sparse parameters, for over twenty real-time recommendation services at Baidu, Inc. In JIZHI, the inference workflow of every recommendation request is transformed to a Staged Event-Driven Pipeline (SEDP), where each node in the pipeline refers to a staged computation or I/O intensive task processor. With traffics of real-time inference requests arrived, each modularized processor can be run in a fully asynchronized way and managed separately. Besides, JIZHI introduces heterogeneous and hierarchical storage to further accelerate the online inference process by reducing unnecessary computations and potential data access latency induced by ultra-sparse model parameters. Moreover, an intelligent resource manager has been deployed to maximize the throughput of JIZHI over the shared infrastructure by searching the optimal resource allocation plan from historical logs and fine-tuning the load shedding policies over intermediate system feedback. Extensive experiments have been done to demonstrate the advantages of JIZHI from the perspectives of end-to-end service latency, system-wide throughput, and resource consumption. JIZHI has helped Baidu saved more than ten million US dollars in hardware and utility costs while handling 200% more traffics without sacrificing inference efficiency.