 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredible Remote Sensing Scene Classification Using Evidential Fusion on Aerial-Ground Dual-view Images
Jan 02, 2023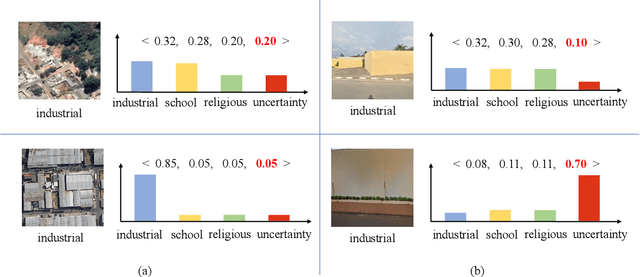



Due to their ability to offer more comprehensive information than data from a single view, multi-view (multi-source, multi-modal, multi-perspective, etc.) data are being used more frequently in remote sensing tasks. However, as the number of views grows, the issue of data quality becomes more apparent, limiting the potential benefits of multi-view data. Although recent deep neural network (DNN) based models can learn the weight of data adaptively, a lack of research on explicitly quantifying the data quality of each view when fusing them renders these models inexplicable, performing unsatisfactorily and inflexible in downstream remote sensing tasks. To fill this gap, in this paper, evidential deep learning is introduced to the task of aerial-ground dual-view remote sensing scene classification to model the credibility of each view. Specifically, the theory of evidence is used to calculate an uncertainty value which describes the decision-making risk of each view. Based on this uncertainty, a novel decision-level fusion strategy is proposed to ensure that the view with lower risk obtains more weight, making the classification more credible. On two well-known, publicly available datasets of aerial-ground dual-view remote sensing images, the proposed approach achieves state-of-the-art results, demonstrating its effectiveness. The code and datasets of this article are available at the following address: https://github.com/gaopiaoliang/Evidential.
Bounding Boxes Are All We Need: Street View Image Classification via Context Encoding of Detected Buildings
Oct 12, 2020
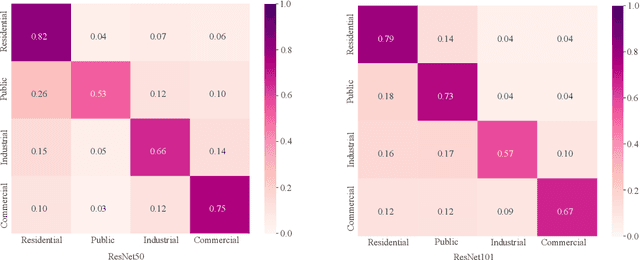
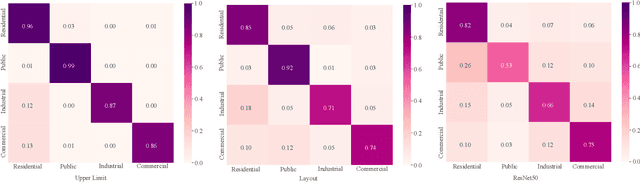

Street view images classification aiming at urban land use analysis is difficult because the class labels (e.g., commercial area), are concepts with higher abstract level compared to the ones of general visual tasks (e.g., persons and cars). Therefore, classification models using only visual features often fail to achieve satisfactory performance. In this paper, a novel approach based on a "Detector-Encoder-Classifier" framework is proposed. Instead of using visual features of the whole image directly as common image-level models based on convolutional neural networks (CNNs) do, the proposed framework firstly obtains the bounding boxes of buildings in street view images from a detector. Their contextual information such as the co-occurrence patterns of building classes and their layout are then encoded into metadata by the proposed algorithm "CODING" (Context encOding of Detected buildINGs). Finally, these bounding box metadata are classified by a recurrent neural network (RNN). In addition, we made a dual-labeled dataset named "BEAUTY" (Building dEtection And Urban funcTional-zone portraYing) of 19,070 street view images and 38,857 buildings based on the existing BIC GSV [1]. The dataset can be used not only for street view image classification, but also for multi-class building detection. Experiments on "BEAUTY" show that the proposed approach achieves a 12.65% performance improvement on macro-precision and 12% on macro-recall over image-level CNN based models. Our code and dataset are available at https://github.com/kyle-one/Context-Encoding-of-Detected-Buildings/