 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Interleaving Global Channel Attention for Multilabel Remote Sensing Image Classification
Aug 04, 2022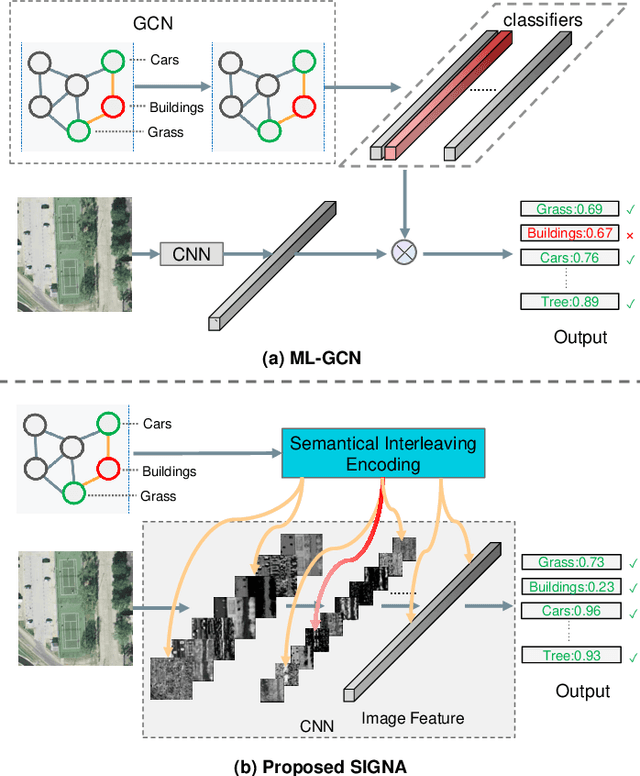
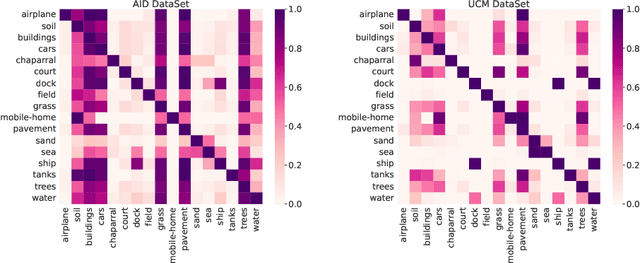
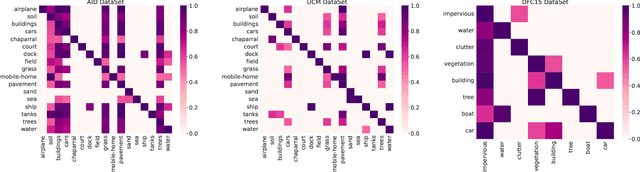
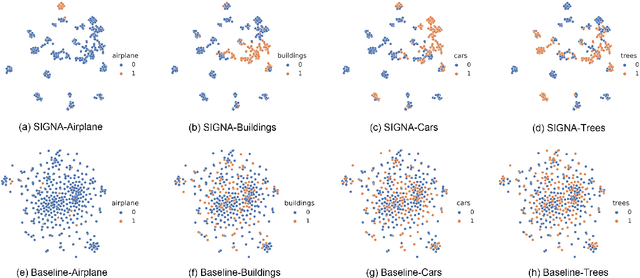
Multi-Label Remote Sensing Image Classification (MLRSIC) has received increasing research interest. Taking the cooccurrence relationship of multiple labels as additional information helps to improve the performance of this task. Current methods focus on using it to constrain the final feature output of a Convolutional Neural Network (CNN). On the one hand, these methods do not make full use of label correlation to form feature representation. On the other hand, they increase the label noise sensitivity of the system, resulting in poor robustness. In this paper, a novel method called Semantic Interleaving Global Channel Attention (SIGNA) is proposed for MLRSIC. First, the label co-occurrence graph is obtained according to the statistical information of the data set. The label co-occurrence graph is used as the input of the Graph Neural Network (GNN) to generate optimal feature representations. Then, the semantic features and visual features are interleaved, to guide the feature expression of the image from the original feature space to the semantic feature space with embedded label relations. SIGNA triggers global attention of feature maps channels in a new semantic feature space to extract more important visual features. Multihead SIGNA based feature adaptive weighting networks are proposed to act on any layer of CNN in a plug-and-play manner. For remote sensing images, better classification performance can be achieved by inserting CNN into the shallow layer. We conduct extensive experimental comparisons on three data sets: UCM data set, AID data set, and DFC15 data set. Experimental results demonstrate that the proposed SIGNA achieves superior classification performance compared to state-of-the-art (SOTA) methods. It is worth mentioning that the codes of this paper will be open to the community for reproducibility research. Our codes are available at https://github.com/kyle-one/SIGNA.
Bounding Boxes Are All We Need: Street View Image Classification via Context Encoding of Detected Buildings
Oct 12, 2020
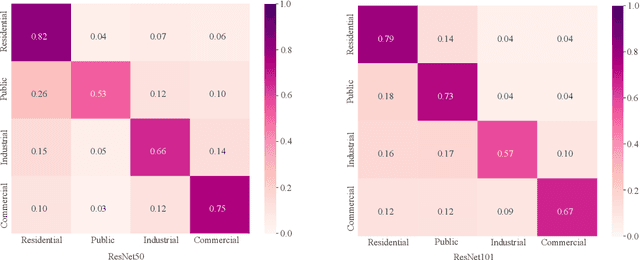
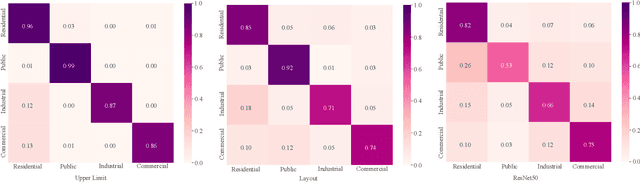

Street view images classification aiming at urban land use analysis is difficult because the class labels (e.g., commercial area), are concepts with higher abstract level compared to the ones of general visual tasks (e.g., persons and cars). Therefore, classification models using only visual features often fail to achieve satisfactory performance. In this paper, a novel approach based on a "Detector-Encoder-Classifier" framework is proposed. Instead of using visual features of the whole image directly as common image-level models based on convolutional neural networks (CNNs) do, the proposed framework firstly obtains the bounding boxes of buildings in street view images from a detector. Their contextual information such as the co-occurrence patterns of building classes and their layout are then encoded into metadata by the proposed algorithm "CODING" (Context encOding of Detected buildINGs). Finally, these bounding box metadata are classified by a recurrent neural network (RNN). In addition, we made a dual-labeled dataset named "BEAUTY" (Building dEtection And Urban funcTional-zone portraYing) of 19,070 street view images and 38,857 buildings based on the existing BIC GSV [1]. The dataset can be used not only for street view image classification, but also for multi-class building detection. Experiments on "BEAUTY" show that the proposed approach achieves a 12.65% performance improvement on macro-precision and 12% on macro-recall over image-level CNN based models. Our code and dataset are available at https://github.com/kyle-one/Context-Encoding-of-Detected-Buildings/