 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking and Tuning Pre-trained Models: A New Paradigm of Exploiting Model Hubs
Paper and Code
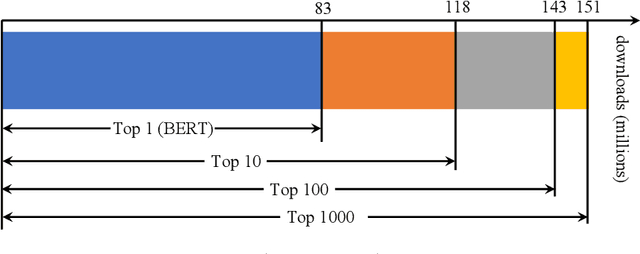
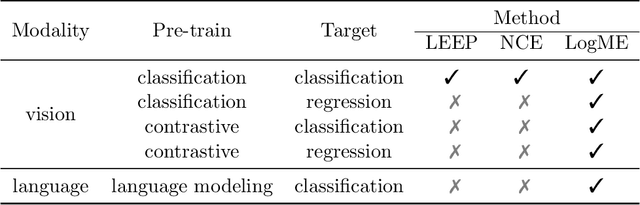
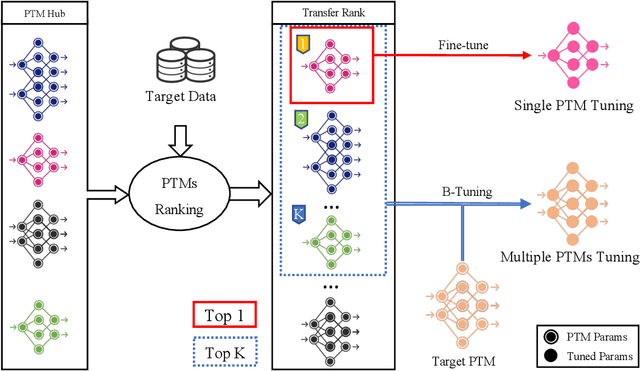
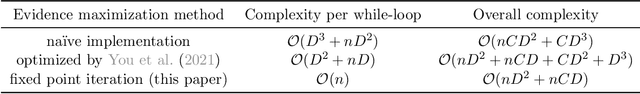
Pre-trained model hubs with many pre-trained models (PTMs) have been a cornerstone in deep learning. Although built at a high cost, they are in fact \emph{under-exploited}: practitioners usually pick one PTM from the provided model hub by popularity, and then fine-tune the PTM to solve the target task. This na\"ve but common practice poses two obstacles to sufficiently exploiting pre-trained model hubs: (1) the PTM selection procedure has no optimality guarantee; (2) only one PTM is used while the rest PTMs are overlooked. Ideally, to maximally exploit pre-trained model hubs, trying all combinations of PTMs and extensively fine-tuning each combination of PTMs are required, which incurs exponential combinations and unaffordable computational budget. In this paper, we propose a new paradigm of exploiting model hubs by ranking and tuning pre-trained models: (1) Our conference work~\citep{you_logme:_2021} proposed LogME to estimate the maximum value of label evidence given features extracted by pre-trained models, which can rank all the PTMs in a model hub for various types of PTMs and tasks \emph{before fine-tuning}. (2) the best ranked PTM can be fine-tuned and deployed if we have no preference for the model's architecture, or the target PTM can be tuned by top-K ranked PTMs via the proposed B-Tuning algorithm. The ranking part is based on the conference paper, and we complete its theoretical analysis (convergence proof of the heuristic evidence maximization procedure, and the influence of feature dimension) in this paper. The tuning part introduces a novel Bayesian Tuning (B-Tuning) method for multiple PTMs tuning, which surpasses dedicated methods designed for homogeneous PTMs tuning and sets up new state of the art for heterogeneous PTMs tuning. We believe the new paradigm of exploiting PTM hubs can interest a large audience of the community.