 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogME: Practical Assessment of Pre-trained Models for Transfer Learning
Paper and Code
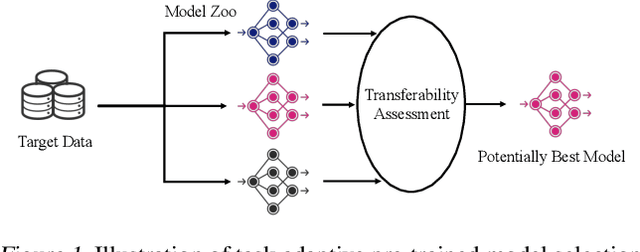
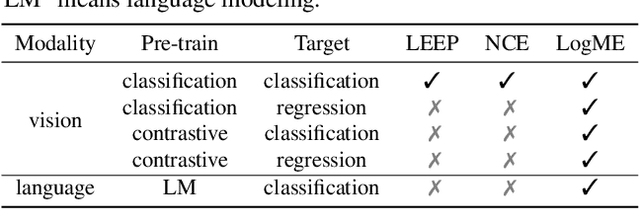
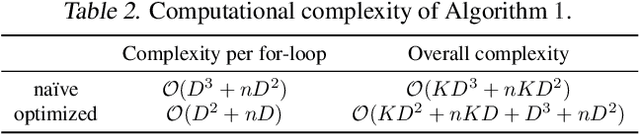
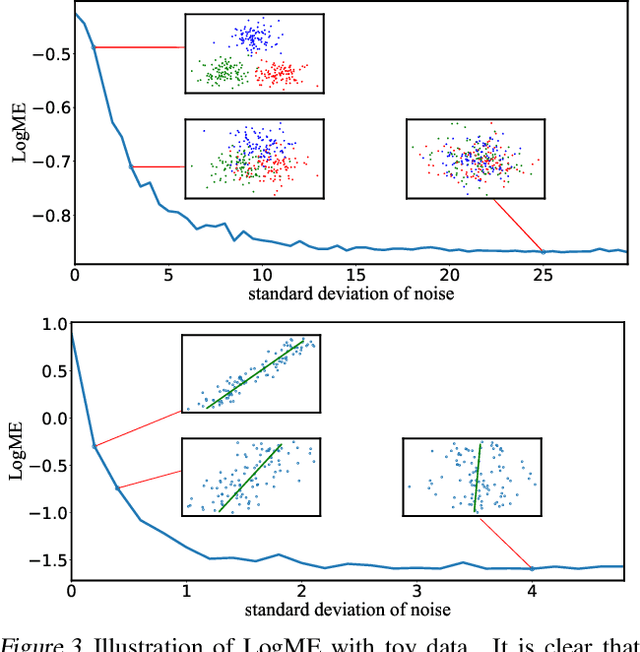
This paper studies task adaptive pre-trained model selection, an \emph{underexplored} problem of assessing pre-trained models so that models suitable for the task can be selected from the model zoo without fine-tuning. A pilot work~\cite{nguyen_leep:_2020} addressed the problem in transferring supervised pre-trained models to classification tasks, but it cannot handle emerging unsupervised pre-trained models or regression tasks. In pursuit of a practical assessment method, we propose to estimate the maximum evidence (marginalized likelihood) of labels given features extracted by pre-trained models. The maximum evidence is \emph{less prone to over-fitting} than the likelihood, and its \emph{expensive computation can be dramatically reduced} by our carefully designed algorithm. The Logarithm of Maximum Evidence (LogME) can be used to assess pre-trained models for transfer learning: a pre-trained model with high LogME is likely to have good transfer performance. LogME is fast, accurate, and general, characterizing it as \emph{the first practical assessment method for transfer learning}. Compared to brute-force fine-tuning, LogME brings over $3000\times$ speedup in wall-clock time. It outperforms prior methods by a large margin in their setting and is applicable to new settings that prior methods cannot deal with. It is general enough to diverse pre-trained models (supervised pre-trained and unsupervised pre-trained), downstream tasks (classification and regression), and modalities (vision and language). Code is at \url{https://github.com/thuml/LogME}.