 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRiffusion: Draft-and-Refine Process Parallelizes Diffusion Models with Ease
Mar 26, 2026Diffusion models have achieved remarkable success in generating high-fidelity content but suffer from slow, iterative sampling, resulting in high latency that limits their use in interactive applications. We introduce DRiffusion, a parallel sampling framework that parallelizes diffusion inference through a draft-and-refine process. DRiffusion employs skip transitions to generate multiple draft states for future timesteps and computes their corresponding noises in parallel, which are then used in the standard denoising process to produce refined results. Theoretically, our method achieves an acceleration rate of $\tfrac{1}{n}$ or $\tfrac{2}{n+1}$, depending on whether the conservative or aggressive mode is used, where $n$ denotes the number of devices. Empirically, DRiffusion attains 1.4$\times$-3.7$\times$ speedup across multiple diffusion models while incur minimal degradation in generation quality: on MS-COCO dataset, both FID and CLIP remain largely on par with those of the original model, while PickScore and HPSv2.1 show only minor average drops of 0.17 and 0.43, respectively. These results verify that DRiffusion delivers substantial acceleration and preserves perceptual quality.
SKIM: Any-bit Quantization Pushing The Limits of Post-Training Quantization
Dec 05, 2024
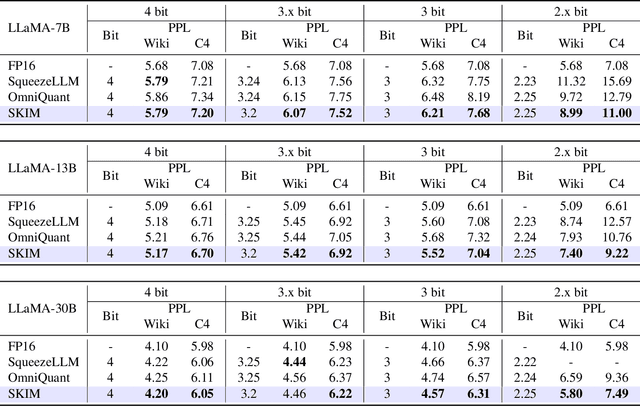

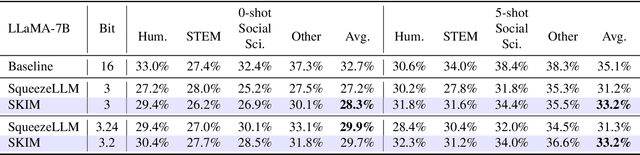
Large Language Models (LLMs) exhibit impressive performance across various tasks, but deploying them for inference poses challenges. Their high resource demands often necessitate complex, costly multi-GPU pipelines, or the use of smaller, less capable models. While quantization offers a promising solution utilizing lower precision for model storage, existing methods frequently experience significant performance drops at lower precision levels. Additionally, they typically provide only a limited set of solutions at specific bit levels, many of which are extensively manually tuned. To address these challenges, we propose a new method called SKIM: Scaled K-means clustering wIth Mixed precision. Our approach introduces two novel techniques: 1. A greedy algorithm to solve approximately optimal bit allocation across weight channels, and 2. A trainable scaling vector for non-differentiable K-means clustering. These techniques substantially improve performance and can be adapted to any given bit. Notably, in terms of model perplexity, our method narrows the gap between 3-bit quantized LLaMA models and their full precision counterparts by 16.3% on average.
depyf: Open the Opaque Box of PyTorch Compiler for Machine Learning Researchers
Mar 14, 2024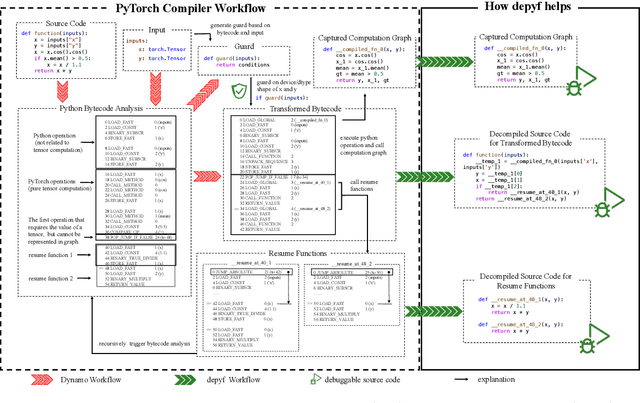


PyTorch \texttt{2.x} introduces a compiler designed to accelerate deep learning programs. However, for machine learning researchers, adapting to the PyTorch compiler to full potential can be challenging. The compiler operates at the Python bytecode level, making it appear as an opaque box. To address this, we introduce \texttt{depyf}, a tool designed to demystify the inner workings of the PyTorch compiler. \texttt{depyf} decompiles bytecode generated by PyTorch back into equivalent source code, and establishes connections between in-memory code objects and their on-disk source code counterparts. This feature enables users to step through the source code line by line using debuggers, thus enhancing their understanding of the underlying processes. Notably, \texttt{depyf} is non-intrusive and user-friendly, primarily relying on two convenient context managers for its core functionality. The project is \href{https://github.com/thuml/depyf}{ openly available} and is recognized as a \href{https://pytorch.org/ecosystem/}{PyTorch ecosystem project}.