 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKIM: Any-bit Quantization Pushing The Limits of Post-Training Quantization
Paper and Code
Dec 05, 2024
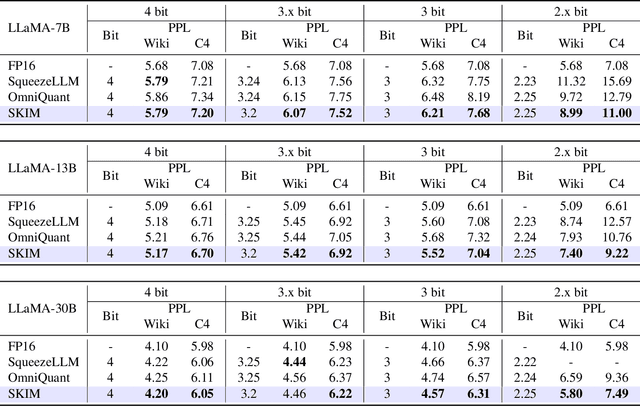

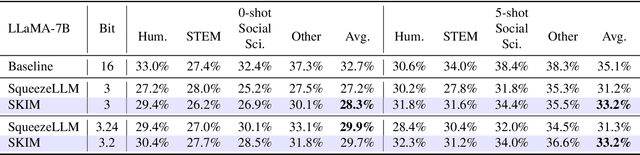
Large Language Models (LLMs) exhibit impressive performance across various tasks, but deploying them for inference poses challenges. Their high resource demands often necessitate complex, costly multi-GPU pipelines, or the use of smaller, less capable models. While quantization offers a promising solution utilizing lower precision for model storage, existing methods frequently experience significant performance drops at lower precision levels. Additionally, they typically provide only a limited set of solutions at specific bit levels, many of which are extensively manually tuned. To address these challenges, we propose a new method called SKIM: Scaled K-means clustering wIth Mixed precision. Our approach introduces two novel techniques: 1. A greedy algorithm to solve approximately optimal bit allocation across weight channels, and 2. A trainable scaling vector for non-differentiable K-means clustering. These techniques substantially improve performance and can be adapted to any given bit. Notably, in terms of model perplexity, our method narrows the gap between 3-bit quantized LLaMA models and their full precision counterparts by 16.3% on average.