 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human Objectives from Sequences of Physical Corrections
Paper and Code
Mar 31, 2021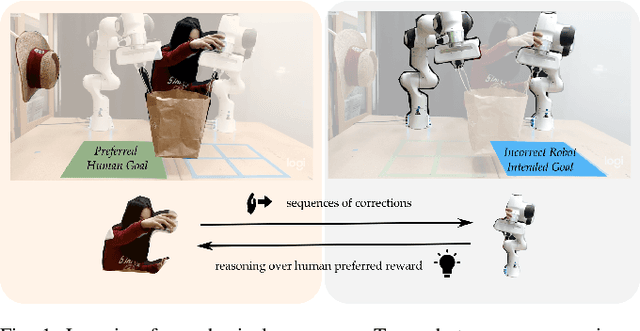
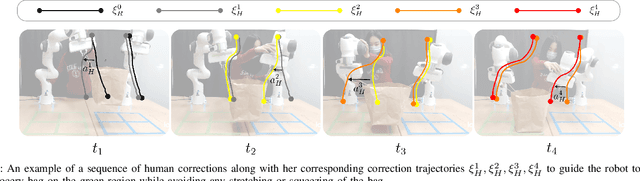
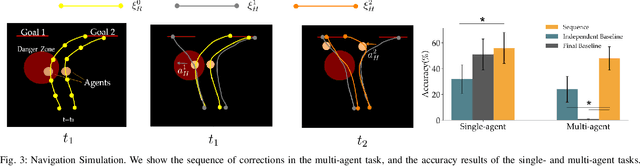
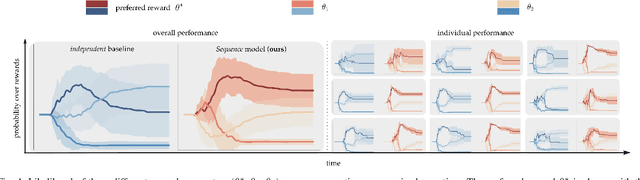
When personal, assistive, and interactive robots make mistakes, humans naturally and intuitively correct those mistakes through physical interaction. In simple situations, one correction is sufficient to convey what the human wants. But when humans are working with multiple robots or the robot is performing an intricate task often the human must make several corrections to fix the robot's behavior. Prior research assumes each of these physical corrections are independent events, and learns from them one-at-a-time. However, this misses out on crucial information: each of these interactions are interconnected, and may only make sense if viewed together. Alternatively, other work reasons over the final trajectory produced by all of the human's corrections. But this method must wait until the end of the task to learn from corrections, as opposed to inferring from the corrections in an online fashion. In this paper we formalize an approach for learning from sequences of physical corrections during the current task. To do this we introduce an auxiliary reward that captures the human's trade-off between making corrections which improve the robot's immediate reward and long-term performance. We evaluate the resulting algorithm in remote and in-person human-robot experiments, and compare to both independent and final baselines. Our results indicate that users are best able to convey their objective when the robot reasons over their sequence of corrections.