 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Latent Actions to Control Assistive Robots
Paper and Code
Jul 10, 2021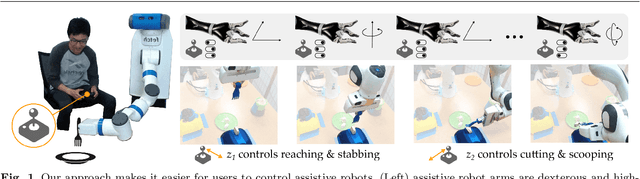

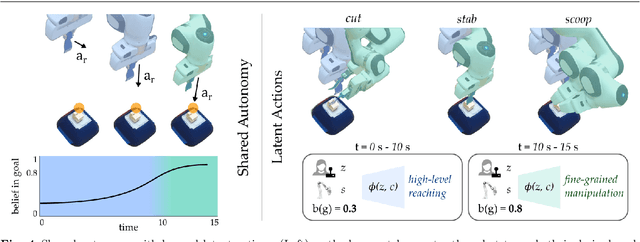
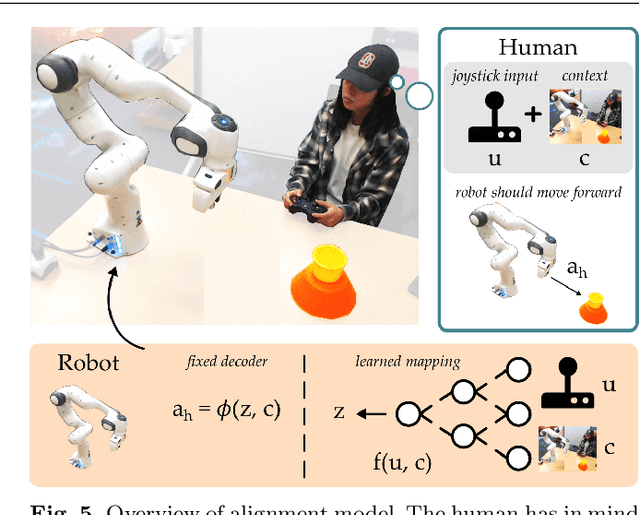
Assistive robot arms enable people with disabilities to conduct everyday tasks on their own. These arms are dexterous and high-dimensional; however, the interfaces people must use to control their robots are low-dimensional. Consider teleoperating a 7-DoF robot arm with a 2-DoF joystick. The robot is helping you eat dinner, and currently you want to cut a piece of tofu. Today's robots assume a pre-defined mapping between joystick inputs and robot actions: in one mode the joystick controls the robot's motion in the x-y plane, in another mode the joystick controls the robot's z-yaw motion, and so on. But this mapping misses out on the task you are trying to perform! Ideally, one joystick axis should control how the robot stabs the tofu and the other axis should control different cutting motions. Our insight is that we can achieve intuitive, user-friendly control of assistive robots by embedding the robot's high-dimensional actions into low-dimensional and human-controllable latent actions. We divide this process into three parts. First, we explore models for learning latent actions from offline task demonstrations, and formalize the properties that latent actions should satisfy. Next, we combine learned latent actions with autonomous robot assistance to help the user reach and maintain their high-level goals. Finally, we learn a personalized alignment model between joystick inputs and latent actions. We evaluate our resulting approach in four user studies where non-disabled participants reach marshmallows, cook apple pie, cut tofu, and assemble dessert. We then test our approach with two disabled adults who leverage assistive devices on a daily basis.